Preprocessing Bias Mitigation Techniques
Load Data
import sys
import os
# Add the root directory of the project to PYTHONPATH
sys.path.append(os.path.abspath(os.path.join('../../master-thesis-dizio-ay2324')))
import numpy as np
import pandas as pd
from pandas.plotting import parallel_coordinates
import matplotlib.pyplot as plt
from collections import defaultdict
from tqdm import tqdm
import seaborn as sns
from matplotlib import rcParams
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.ensemble import HistGradientBoostingClassifier, VotingClassifier
from sklearn.metrics import (
accuracy_score, precision_score, recall_score,
f1_score, roc_auc_score
)
from imblearn.ensemble import BalancedRandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from fairlib import DataFrame
from fairlib.preprocessing import DisparateImpactRemover
from fairlib.preprocessing import ReweighingWithMean, Reweighing
from fairlearn.metrics import (
demographic_parity_ratio,
equalized_odds_ratio,
demographic_parity_difference,
equalized_odds_difference
)
from utils.plot import plot_metrics, plot_metrics_grouped, get_mean_std, print_fairness_results_table
random_state = 42
np.random.seed(random_state)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 21
14 from sklearn.metrics import (
15 accuracy_score, precision_score, recall_score,
16 f1_score, roc_auc_score
17 )
19 from imblearn.ensemble import BalancedRandomForestClassifier
---> 21 from xgboost import XGBClassifier
22 from lightgbm import LGBMClassifier
23 from catboost import CatBoostClassifier
ModuleNotFoundError: No module named 'xgboost'
df_cleaned = pd.read_csv('cleaned_dataset.csv')
features = [
# Base Attributes
"Sex_int",
"Protected category",
"Overall",
"Technical Skills",
"Standing/Position",
"Comunication",
"Maturity",
"Dynamism",
"Mobility",
"English",
"Italian Residence",
"European Residence",
"Age Range_int",
"number_of_searches",
# Custom Similarity Scores
"experience_match_score",
"current_salary_fit_score",
"expected_salary_fit_score",
"study_title_score",
"professional_similarity_score",
"study_area_score",
"general_similarity_score",
"Distance Residence - Akkodis HQ",
"Distance Residence - Assumption HQ",
]
protected_attributes = [
'Sex_int', 'Protected category', 'Age Range_int',
'Italian Residence', 'European Residence'
]
Model
models = {
'HistGradientBoosting': lambda: HistGradientBoostingClassifier(random_state=random_state),
'XGBoost': lambda: XGBClassifier(scale_pos_weight=(y_train == 0).sum() / (y_train == 1).sum(), random_state=random_state, eval_metric='logloss', max_depth=6),
'LightGBM': lambda: LGBMClassifier(class_weight='balanced', random_state=random_state, max_depth=6, min_data_in_leaf=20, verbosity=-1),
'CatBoost': lambda: CatBoostClassifier(auto_class_weights='Balanced', silent=True, random_state=random_state, l2_leaf_reg=3, iterations=500, depth=6, learning_rate=0.05),
'BalancedRF': lambda: BalancedRandomForestClassifier(random_state=random_state)
}
ensemble = lambda: VotingClassifier(
estimators=[
('xgb', models['XGBoost']()),
('lgbm', models['LightGBM']()),
('cat', models['CatBoost']()),
('hist', models['HistGradientBoosting']()),
('brf', models['BalancedRF']())
],
voting='soft'
)
Disparate Impact Remover
results = defaultdict(list)
plot_data = defaultdict(dict)
n_folds = 5
repair_levels = [0.0, 0.5, 1]
dataset = pd.DataFrame(df_cleaned[features + ['Hired']])
bool_cols = dataset.select_dtypes(include='bool').columns
non_bool_cols = dataset[features].columns.difference(bool_cols)
dataset[bool_cols] = dataset[bool_cols].astype(int)
kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42)
for fold, (train_idx, test_idx) in tqdm(enumerate(kf.split(dataset[features], dataset['Hired']))):
X_train, X_test = dataset.iloc[train_idx][features], dataset.iloc[test_idx][features]
y_train, y_test = dataset.iloc[train_idx]['Hired'], dataset.iloc[test_idx]['Hired']
imputer = SimpleImputer(strategy='mean')
X_train = pd.DataFrame(imputer.fit_transform(X_train), columns=X_train.columns)
X_test = pd.DataFrame(imputer.transform(X_test), columns=X_test.columns)
scaler = StandardScaler()
X_train[non_bool_cols] = scaler.fit_transform(X_train[non_bool_cols])
X_test[non_bool_cols] = scaler.transform(X_test[non_bool_cols])
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
dir = DisparateImpactRemover(repair_level=repair_level)
X_train_df = DataFrame(X_train)
X_train_df.sensitive = sensitive_attr
X_test_df = DataFrame(X_test)
X_test_df.sensitive = sensitive_attr
X_train_transormed = dir.fit_transform(X_train_df)
sensitive_idx = list(X_train_df.columns).index(sensitive_attr)
X_test_transormed = pd.DataFrame(dir.transform(X_test.to_numpy(), sensitive_idxs=[sensitive_idx]), columns=X_test_df.columns)
X_test_transormed = DataFrame(X_test_transormed)
X_test_transormed.sensitive = sensitive_attr
clf = ensemble()
clf.fit(X_train_transormed, y_train)
y_pred = clf.predict(X_test_transormed)
y_prob = clf.predict_proba(X_test_transormed)[:, 1]
metrics = {
'accuracy': accuracy_score(y_test, y_pred),
'precision': precision_score(y_test, y_pred, zero_division=0),
'recall': recall_score(y_test, y_pred, zero_division=0),
'f1': f1_score(y_test, y_pred, zero_division=0),
'roc_auc': roc_auc_score(y_test, y_prob),
'demographic_parity_ratio': demographic_parity_ratio(
y_test, y_pred, sensitive_features=X_test_df[sensitive_attr]),
'equalized_odds_ratio': equalized_odds_ratio(
y_test, y_pred, sensitive_features=X_test_df[sensitive_attr]),
'demographic_parity_difference': demographic_parity_difference(
y_test, y_pred, sensitive_features=X_test_df[sensitive_attr]),
'equalized_odds_difference': equalized_odds_difference(
y_test, y_pred, sensitive_features=X_test_df[sensitive_attr]),
}
key = f"{sensitive_attr}_repair_{repair_level}"
results[key].append(metrics)
if repair_level>0:
key = f"{sensitive_attr}_repair_{repair_level}"
X_test_raw = X_test.copy()
X_test_transformed = X_test_transormed.copy()
X_test_raw['type'] = 'Original'
X_test_transformed['type'] = 'Transformed'
combined = pd.concat([X_test_raw, X_test_transformed], axis=0)
plt.figure(figsize=(14, 6))
parallel_coordinates(combined, class_column='type', color=['blue', 'red'], alpha=0.3)
plt.title(f'Coordinate Plot - {sensitive_attr} - Repair Level {repair_level} - Fold {fold}')
plt.ylabel("Normalized Feature Value")
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.show()
metrics_keys = list(metrics.keys())
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
key = f"{sensitive_attr}_repair_{repair_level}"
fold_metrics = results.get(key, [])
for metric in metrics_keys:
metric_list = [m[metric] for m in fold_metrics]
mean, std = get_mean_std(metric_list)
plot_data[sensitive_attr][f"{metric}_mean_{repair_level}"] = mean
plot_data[sensitive_attr][f"{metric}_std_{repair_level}"] = std
0it [00:00, ?it/s]
1it [01:36, 96.40s/it]

2it [03:06, 92.78s/it]
3it [04:49, 97.55s/it]

4it [06:32, 99.52s/it]
5it [08:15, 99.05s/it]
print_fairness_results_table(plot_data, metrics_keys, repair_levels)
=== Results for sensitive attribute: Sex_int ===
Repair 0.0 Repair 0.5 Repair 1
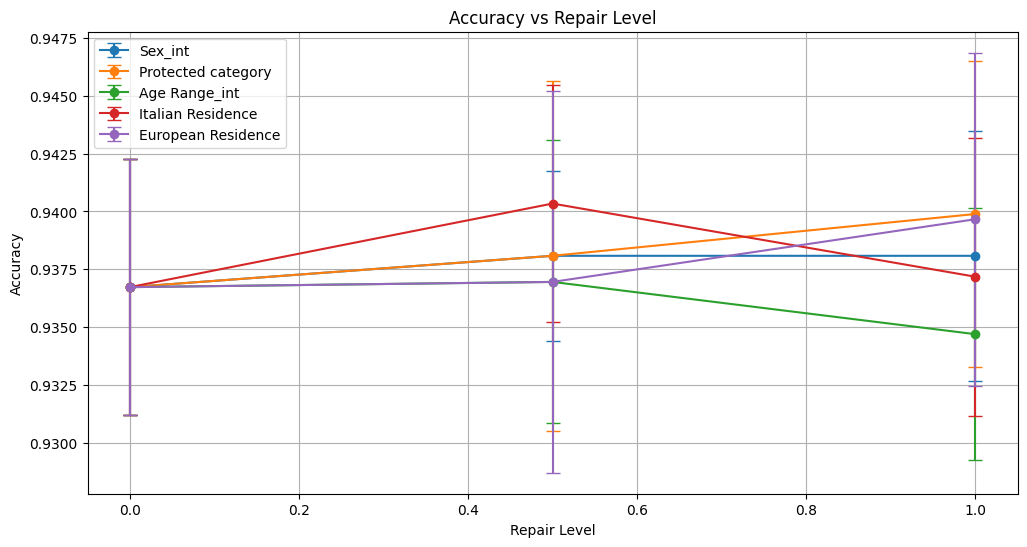
accuracy 0.937 ± 0.006 0.938 ± 0.004 0.938 ± 0.005
precision 0.693 ± 0.026 0.698 ± 0.021 0.701 ± 0.026
recall 0.733 ± 0.061 0.741 ± 0.048 0.730 ± 0.048
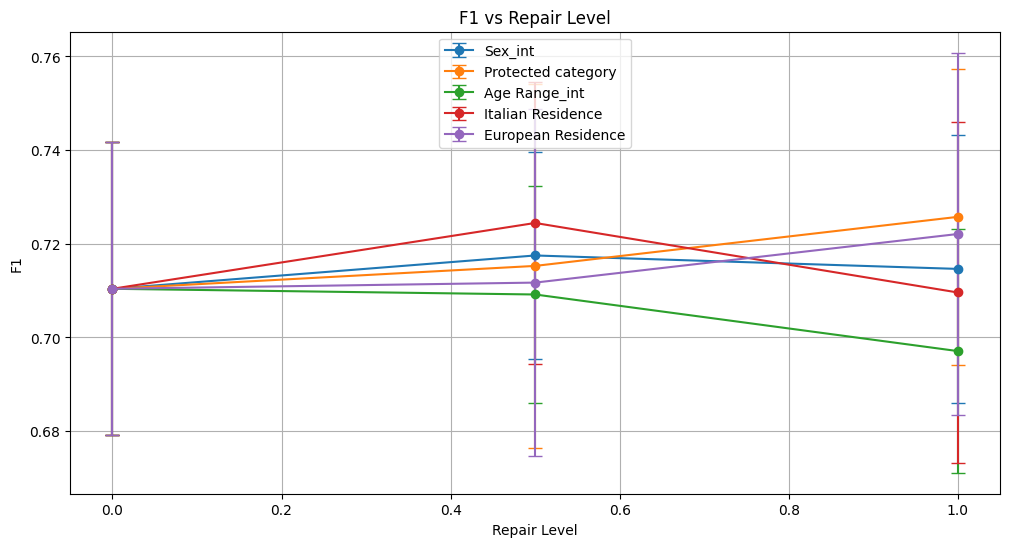
f1 0.710 ± 0.031 0.718 ± 0.022 0.715 ± 0.029
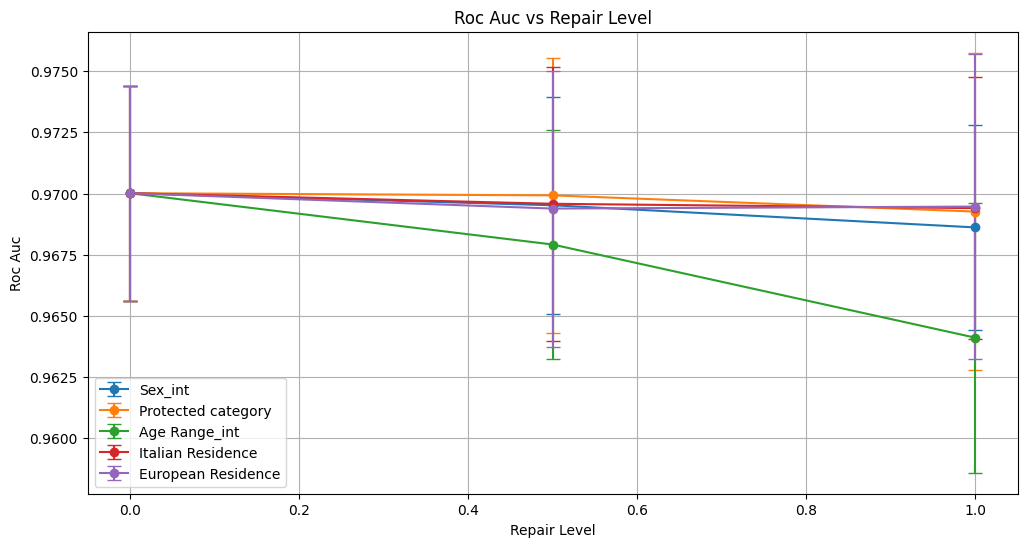
roc_auc 0.970 ± 0.004 0.970 ± 0.004 0.969 ± 0.004
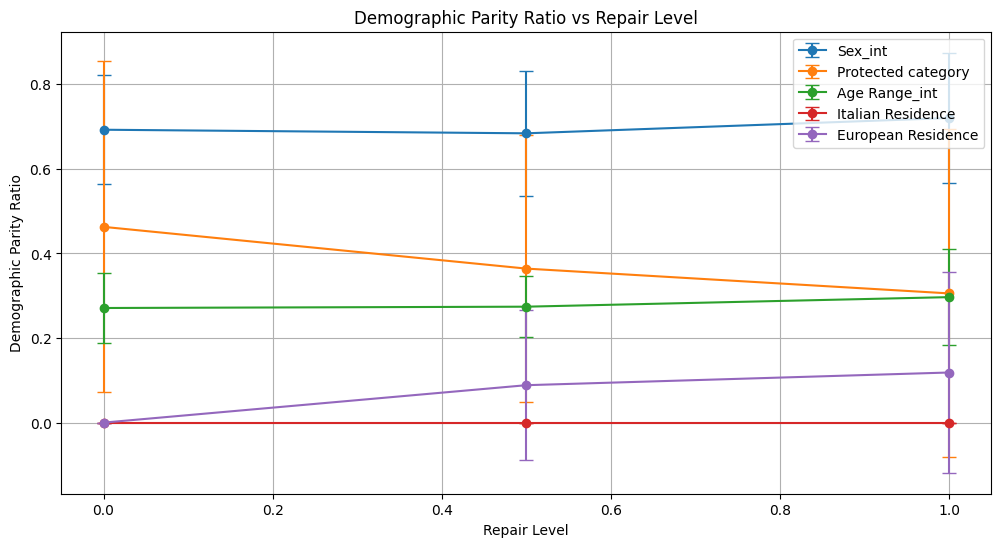
demographic_parity_ratio 0.693 ± 0.129 0.684 ± 0.148 0.720 ± 0.154
equalized_odds_ratio 0.776 ± 0.106 0.722 ± 0.069 0.760 ± 0.085
demographic_parity_difference 0.048 ± 0.021 0.051 ± 0.026 0.043 ± 0.026
equalized_odds_difference 0.094 ± 0.042 0.127 ± 0.068 0.130 ± 0.062
=== Results for sensitive attribute: Protected category ===
Repair 0.0 Repair 0.5 Repair 1
accuracy 0.937 ± 0.006 0.938 ± 0.008 0.940 ± 0.007
precision 0.693 ± 0.026 0.701 ± 0.037 0.707 ± 0.036
recall 0.733 ± 0.061 0.735 ± 0.069 0.749 ± 0.058
f1 0.710 ± 0.031 0.715 ± 0.039 0.726 ± 0.032
roc_auc 0.970 ± 0.004 0.970 ± 0.006 0.969 ± 0.006
demographic_parity_ratio 0.463 ± 0.392 0.364 ± 0.316 0.306 ± 0.388
equalized_odds_ratio 0.000 ± 0.000 0.044 ± 0.087 0.000 ± 0.000
demographic_parity_difference 0.068 ± 0.045 0.090 ± 0.035 0.089 ± 0.043
equalized_odds_difference 0.456 ± 0.245 0.449 ± 0.252 0.562 ± 0.250
=== Results for sensitive attribute: Age Range_int ===
Repair 0.0 Repair 0.5 Repair 1
accuracy 0.937 ± 0.006 0.937 ± 0.006 0.935 ± 0.005
precision 0.693 ± 0.026 0.700 ± 0.045 0.689 ± 0.029
recall 0.733 ± 0.061 0.722 ± 0.042 0.707 ± 0.043
f1 0.710 ± 0.031 0.709 ± 0.023 0.697 ± 0.026
roc_auc 0.970 ± 0.004 0.968 ± 0.005 0.964 ± 0.006
demographic_parity_ratio 0.271 ± 0.083 0.274 ± 0.072 0.297 ± 0.114
equalized_odds_ratio 0.111 ± 0.111 0.129 ± 0.159 0.197 ± 0.150
demographic_parity_difference 0.159 ± 0.043 0.157 ± 0.035 0.148 ± 0.046
equalized_odds_difference 0.365 ± 0.127 0.431 ± 0.150 0.448 ± 0.164
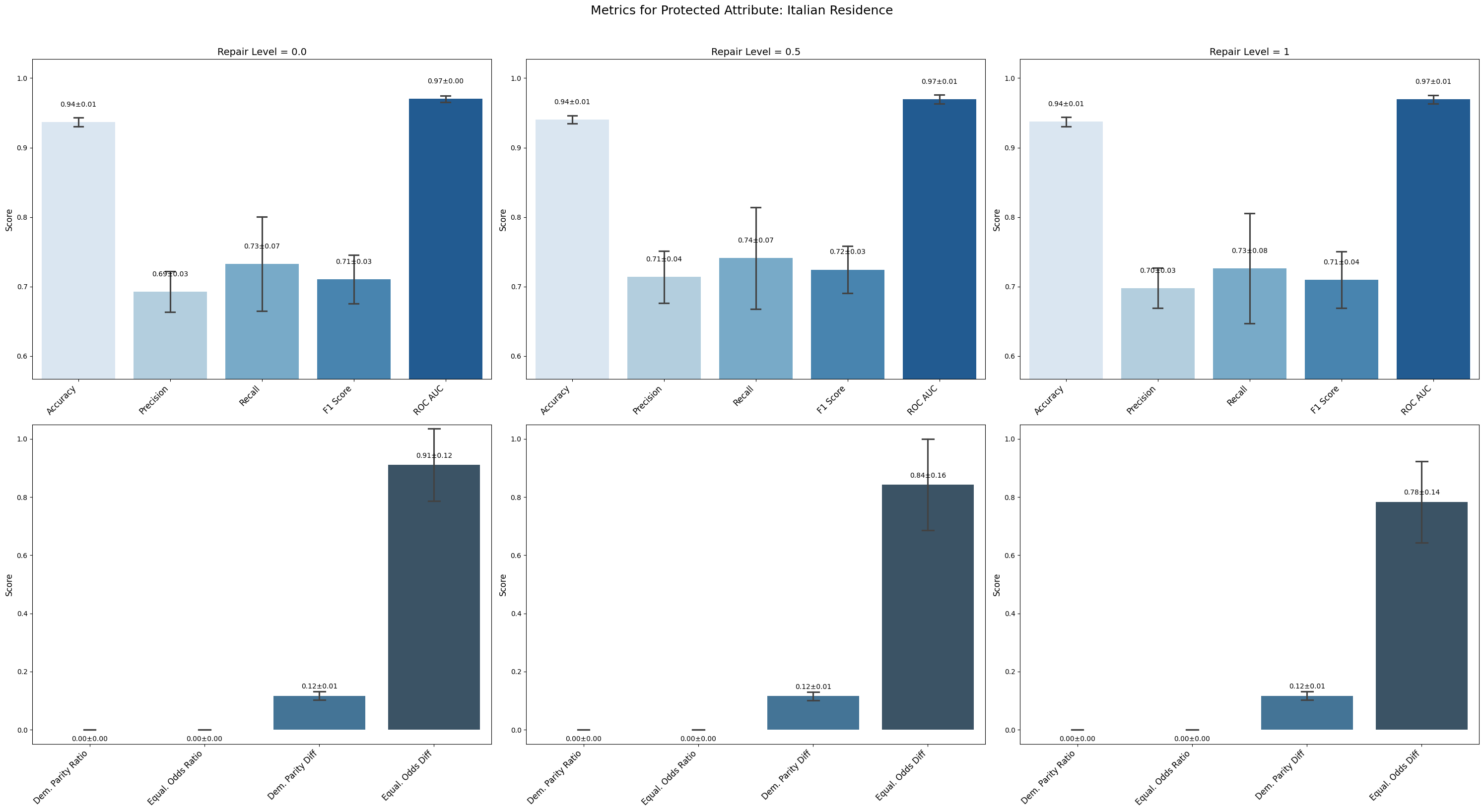
=== Results for sensitive attribute: Italian Residence ===
Repair 0.0 Repair 0.5 Repair 1
accuracy 0.937 ± 0.006 0.940 ± 0.005 0.937 ± 0.006
precision 0.693 ± 0.026 0.714 ± 0.033 0.698 ± 0.026
recall 0.733 ± 0.061 0.741 ± 0.065 0.726 ± 0.071
f1 0.710 ± 0.031 0.724 ± 0.030 0.710 ± 0.036
roc_auc 0.970 ± 0.004 0.970 ± 0.006 0.969 ± 0.005
demographic_parity_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.117 ± 0.013 0.116 ± 0.013 0.116 ± 0.013
equalized_odds_difference 0.911 ± 0.111 0.843 ± 0.140 0.783 ± 0.125
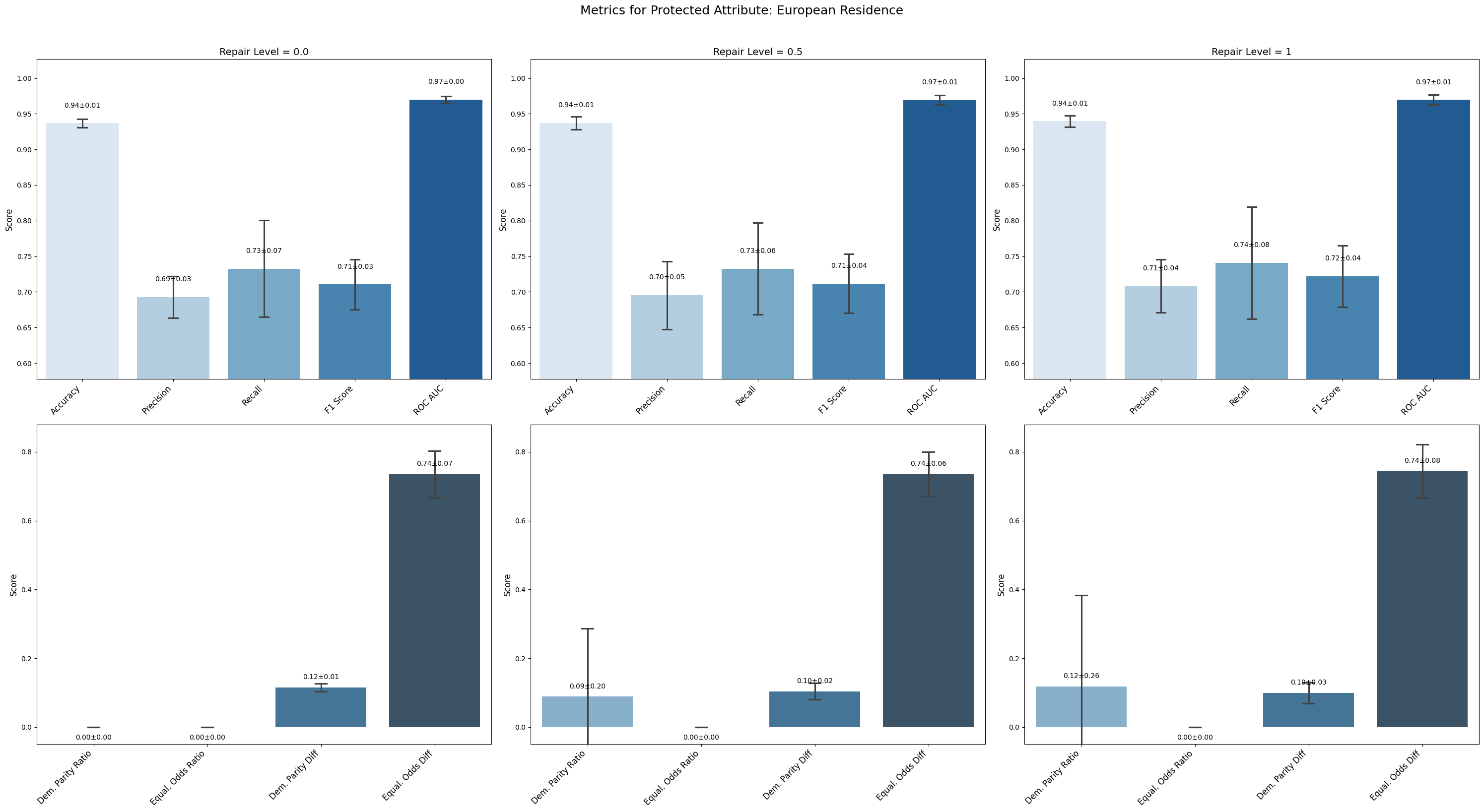
=== Results for sensitive attribute: European Residence ===
Repair 0.0 Repair 0.5 Repair 1
accuracy 0.937 ± 0.006 0.937 ± 0.008 0.940 ± 0.007
precision 0.693 ± 0.026 0.695 ± 0.043 0.708 ± 0.033
recall 0.733 ± 0.061 0.733 ± 0.057 0.741 ± 0.070
f1 0.710 ± 0.031 0.712 ± 0.037 0.722 ± 0.039
roc_auc 0.970 ± 0.004 0.969 ± 0.006 0.969 ± 0.006
demographic_parity_ratio 0.000 ± 0.000 0.089 ± 0.177 0.119 ± 0.237
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.115 ± 0.010 0.104 ± 0.021 0.099 ± 0.027
equalized_odds_difference 0.736 ± 0.061 0.736 ± 0.057 0.744 ± 0.069
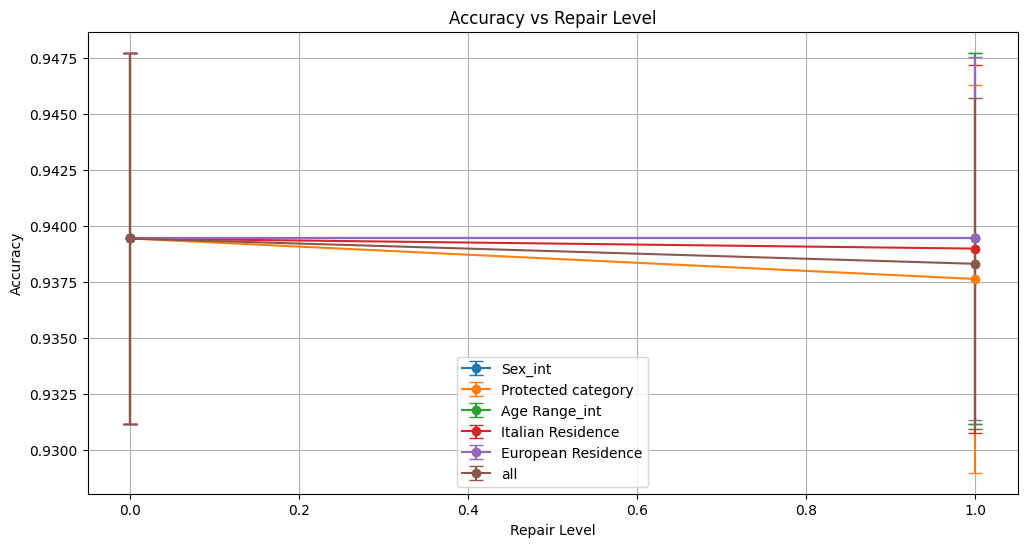
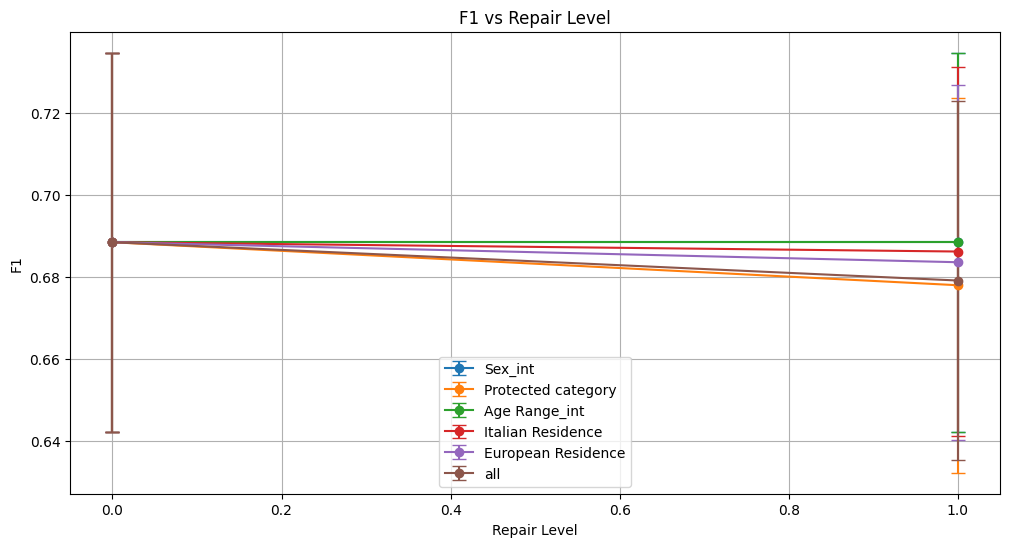
for metric in ['accuracy', 'f1', 'roc_auc', 'demographic_parity_ratio', 'equalized_odds_ratio']:
plot_metrics(plot_data, metric, repair_levels, protected_attributes)
plot_metrics_grouped(results, protected_attributes, repair_levels)
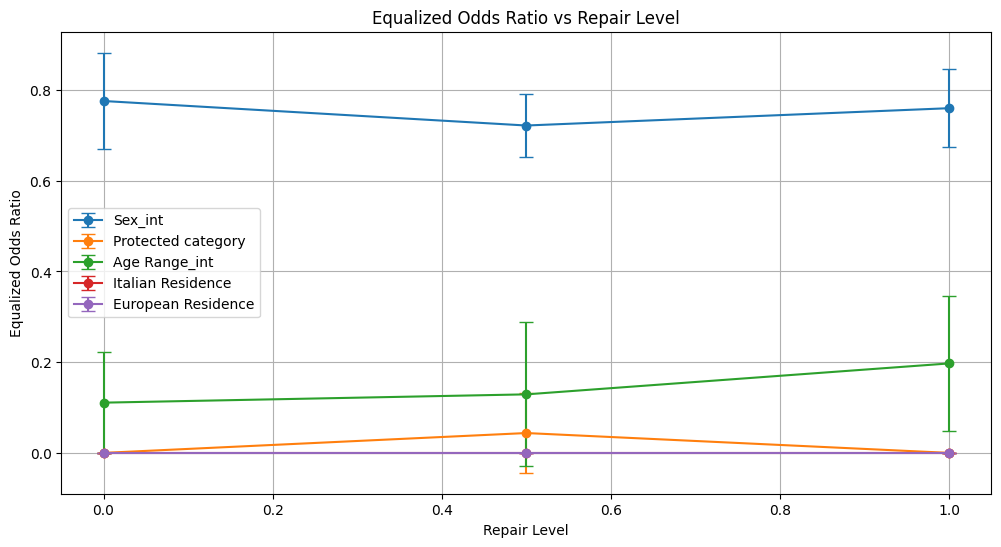
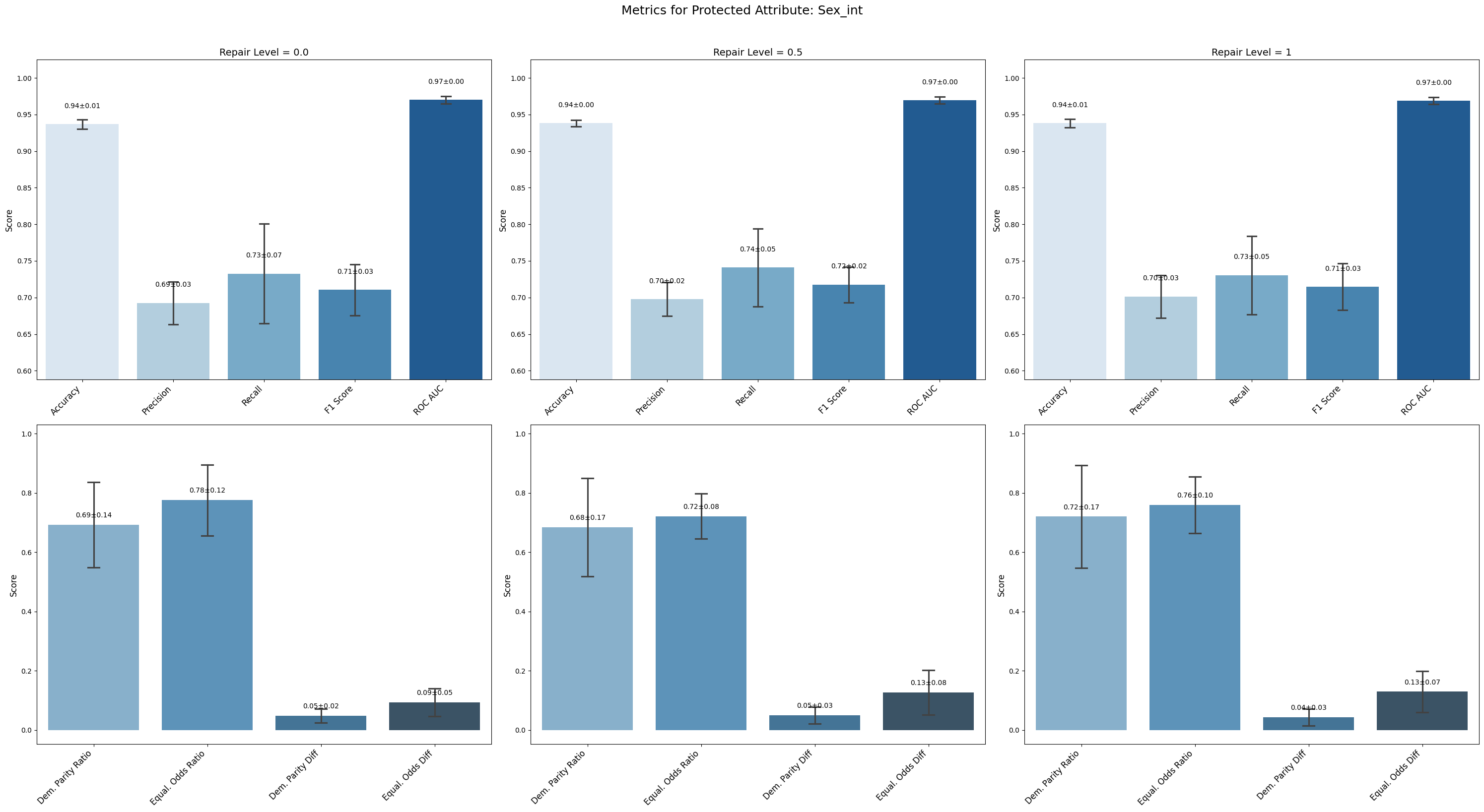
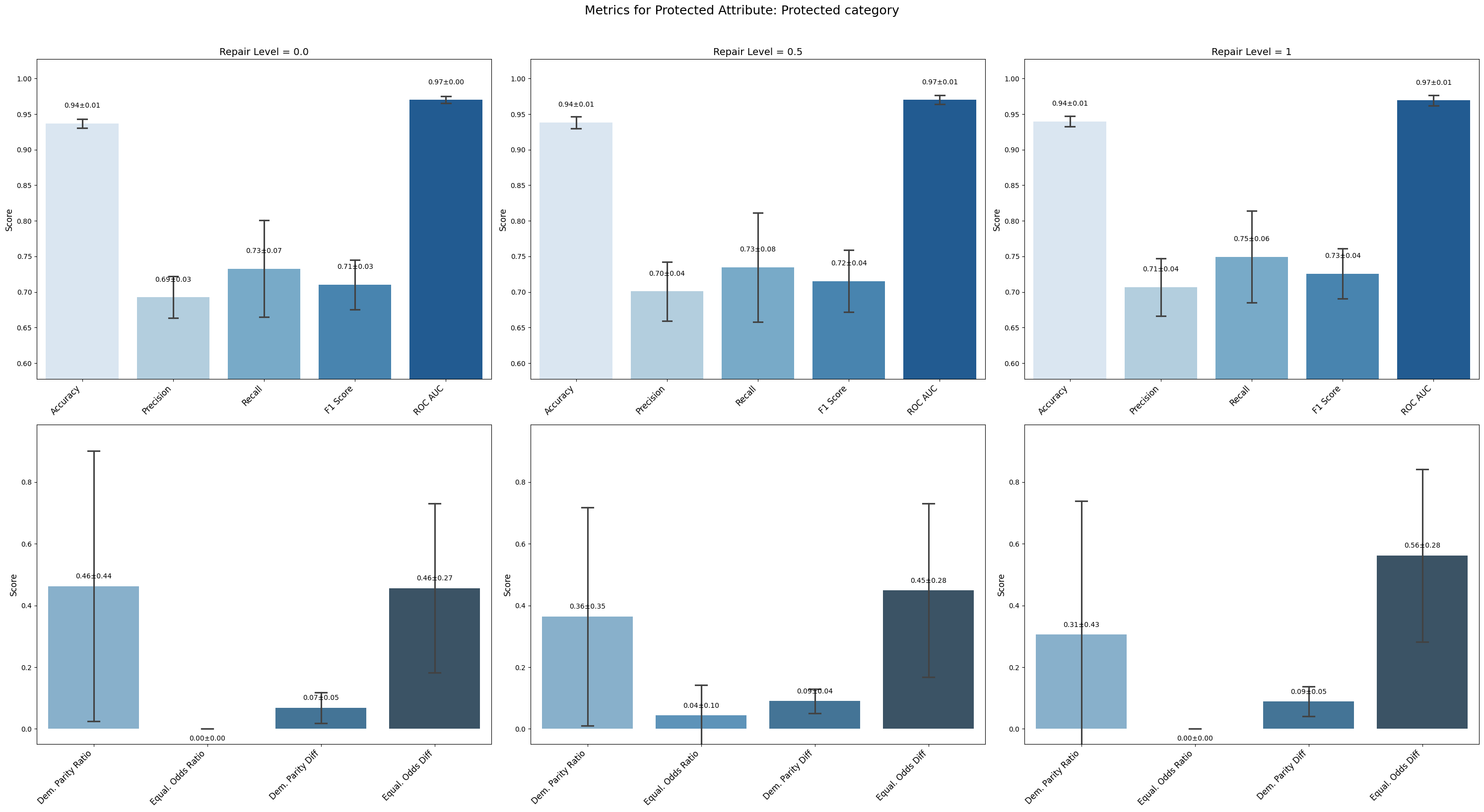
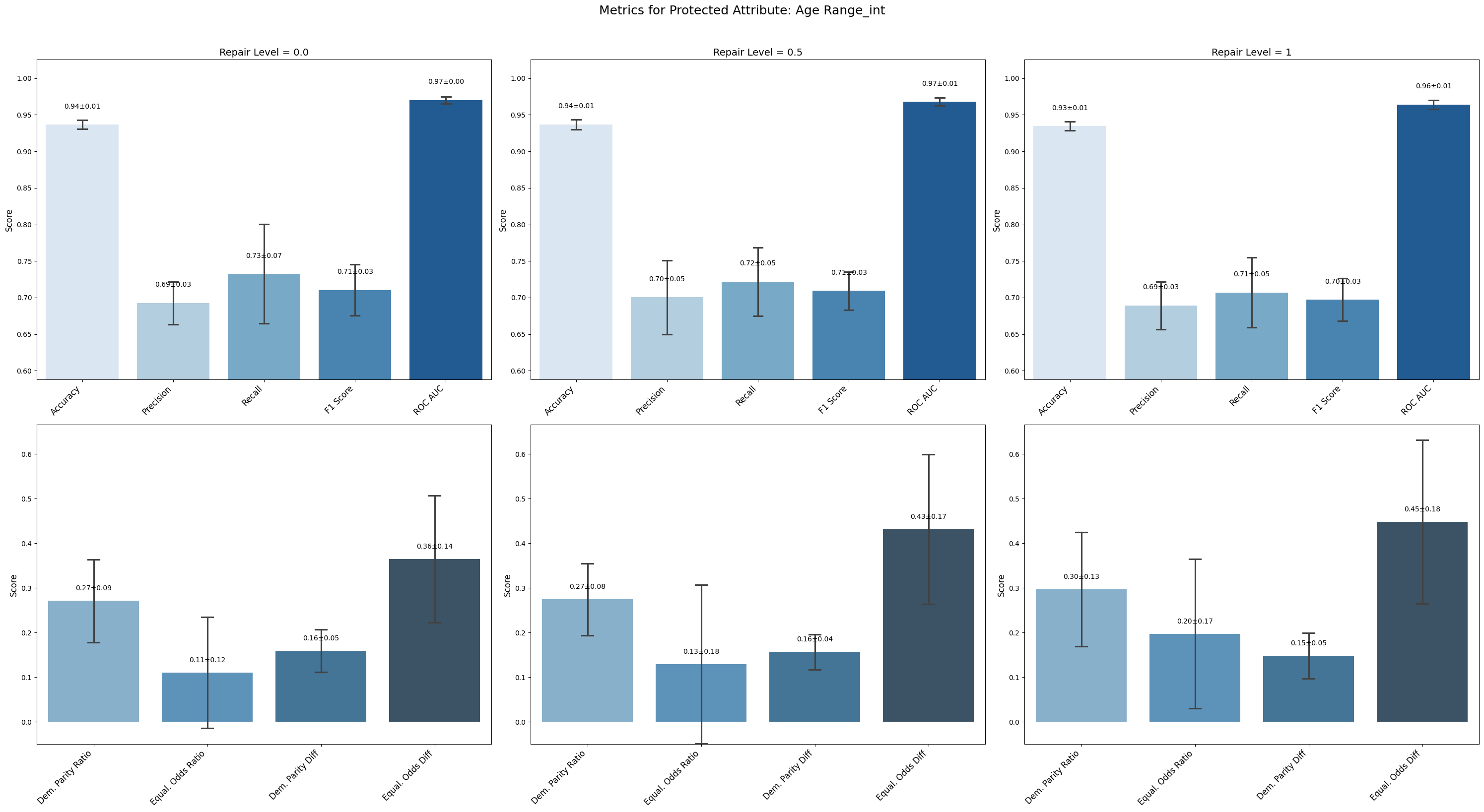
Conclusion on Disparate Impact Remover Technique
The Disparate Impact Remover (DIR) was applied with repair levels 0.0, 0.5, and 1.0 across five sensitive attributes: Sex, Protected Category, Age Range, Italian Residence, and European Residence.
Overall Performance:
Classification metrics—accuracy, precision, recall, F1 score, and ROC AUC—remained largely stable across repair levels, demonstrating that the technique maintains predictive performance without significant degradation.Bias Mitigation:
For Sex_int and Protected Category, small improvements in demographic parity metrics (ratios and differences) were observed as repair increased. However, some trade-offs appeared in equalized odds differences, which slightly increased at higher repair levels, indicating a nuanced fairness-performance balance.
Age Range_int saw modest fairness improvements with increasing repair, such as a rise in demographic parity ratio and equalized odds ratio. These gains came alongside minor decreases in performance metrics like ROC AUC and F1, suggesting a slight trade-off between fairness and accuracy.
For Italian Residence, fairness metrics (demographic parity and equalized odds ratios) remained at zero, showing persistent and unmitigated bias. Equalized odds difference, although slightly decreasing with repair, stayed very high, indicating little effectiveness.
European Residence exhibited very limited fairness improvement; demographic parity ratio increased marginally but equalized odds ratio remained zero, highlighting the technique’s ineffectiveness for this attribute.
Conclusion:
The Disparate Impact Remover provides modest improvements in fairness metrics without compromising overall model performance, especially for Sex and to a lesser extent Protected Category and Age Range. However, it struggles to mitigate bias effectively for geographic attributes (Italian and European Residence), suggesting that complementary or alternative bias mitigation methods are necessary for these cases.
Reweighing
results = defaultdict(list)
plot_data = defaultdict(dict)
n_folds = 5
repair_levels = [0, 1]
dataset = pd.DataFrame(df_cleaned[features + ["Hired"]])
bool_cols = dataset.select_dtypes(include="bool").columns
non_bool_cols = dataset[features].columns.difference(bool_cols)
dataset[bool_cols] = dataset[bool_cols].astype(int)
combined_protected_attributes = protected_attributes + ['all']
kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42)
for fold, (train_idx, test_idx) in tqdm(
enumerate(kf.split(dataset[features], dataset["Hired"]))
):
train_df = dataset.iloc[train_idx]
test_df = dataset.iloc[test_idx]
imputer = SimpleImputer(strategy="mean")
train_df = pd.DataFrame(imputer.fit_transform(train_df), columns=train_df.columns)
test_df = pd.DataFrame(imputer.transform(test_df), columns=test_df.columns)
scaler = StandardScaler()
train_df[non_bool_cols] = scaler.fit_transform(train_df[non_bool_cols])
test_df[non_bool_cols] = scaler.transform(test_df[non_bool_cols])
for sensitive_attr in combined_protected_attributes:
for repair_level in repair_levels:
train_df_transformed = DataFrame(train_df.copy())
test_df_transformed = DataFrame(test_df.copy())
train_df_transformed.sensitive = protected_attributes if sensitive_attr=='all' else sensitive_attr
train_df_transformed.targets = ['Hired']
test_df_transformed.sensitive = protected_attributes if sensitive_attr=='all' else sensitive_attr
test_df_transformed.targets = ['Hired']
y_train = train_df_transformed['Hired']
clf = models['HistGradientBoosting']()
if repair_level == 1:
reweighing = ReweighingWithMean() if sensitive_attr=='all' else Reweighing()
reweighed_df = reweighing.fit_transform(train_df_transformed)
weights = reweighed_df['weights'].values
clf.fit(train_df_transformed[features],train_df_transformed['Hired'], sample_weight=weights)
else:
clf.fit(train_df_transformed[features],train_df_transformed['Hired'])
y_pred = clf.predict(test_df_transformed[features])
y_prob = clf.predict_proba(test_df_transformed[features])[:, 1]
y_test = test_df_transformed['Hired']
X_test = test_df_transformed[features]
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred, zero_division=0),
"recall": recall_score(y_test, y_pred, zero_division=0),
"f1": f1_score(y_test, y_pred, zero_division=0),
"roc_auc": roc_auc_score(y_test, y_prob),
"demographic_parity_ratio": demographic_parity_ratio(
y_test, y_pred, sensitive_features=X_test[protected_attributes if sensitive_attr=='all' else sensitive_attr]
),
"equalized_odds_ratio": equalized_odds_ratio(
y_test, y_pred, sensitive_features=X_test[protected_attributes if sensitive_attr=='all' else sensitive_attr]
),
"demographic_parity_difference": demographic_parity_difference(
y_test, y_pred, sensitive_features=X_test[protected_attributes if sensitive_attr=='all' else sensitive_attr]
),
"equalized_odds_difference": equalized_odds_difference(
y_test, y_pred, sensitive_features=X_test[protected_attributes if sensitive_attr=='all' else sensitive_attr]
),
}
key = f"{sensitive_attr}_repair_{repair_level}"
results[key].append(metrics)
metrics_keys = list(metrics.keys())
for sensitive_attr in combined_protected_attributes:
for repair_level in repair_levels:
key = f"{sensitive_attr}_repair_{repair_level}"
fold_metrics = results.get(key, [])
for metric in metrics_keys:
metric_list = [m[metric] for m in fold_metrics]
mean, std = get_mean_std(metric_list)
plot_data[sensitive_attr][f"{metric}_mean_{repair_level}"] = mean
plot_data[sensitive_attr][f"{metric}_std_{repair_level}"] = std
0it [00:00, ?it/s]
5it [00:35, 7.07s/it]
print_fairness_results_table(plot_data, metrics_keys, repair_levels)
=== Results for sensitive attribute: Sex_int ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.939 ± 0.008
precision 0.759 ± 0.039 0.759 ± 0.039
recall 0.631 ± 0.054 0.631 ± 0.054
f1 0.688 ± 0.046 0.688 ± 0.046
roc_auc 0.968 ± 0.006 0.968 ± 0.006
demographic_parity_ratio 0.627 ± 0.123 0.627 ± 0.123
equalized_odds_ratio 0.645 ± 0.133 0.645 ± 0.133
demographic_parity_difference 0.049 ± 0.021 0.049 ± 0.021
equalized_odds_difference 0.131 ± 0.040 0.131 ± 0.040
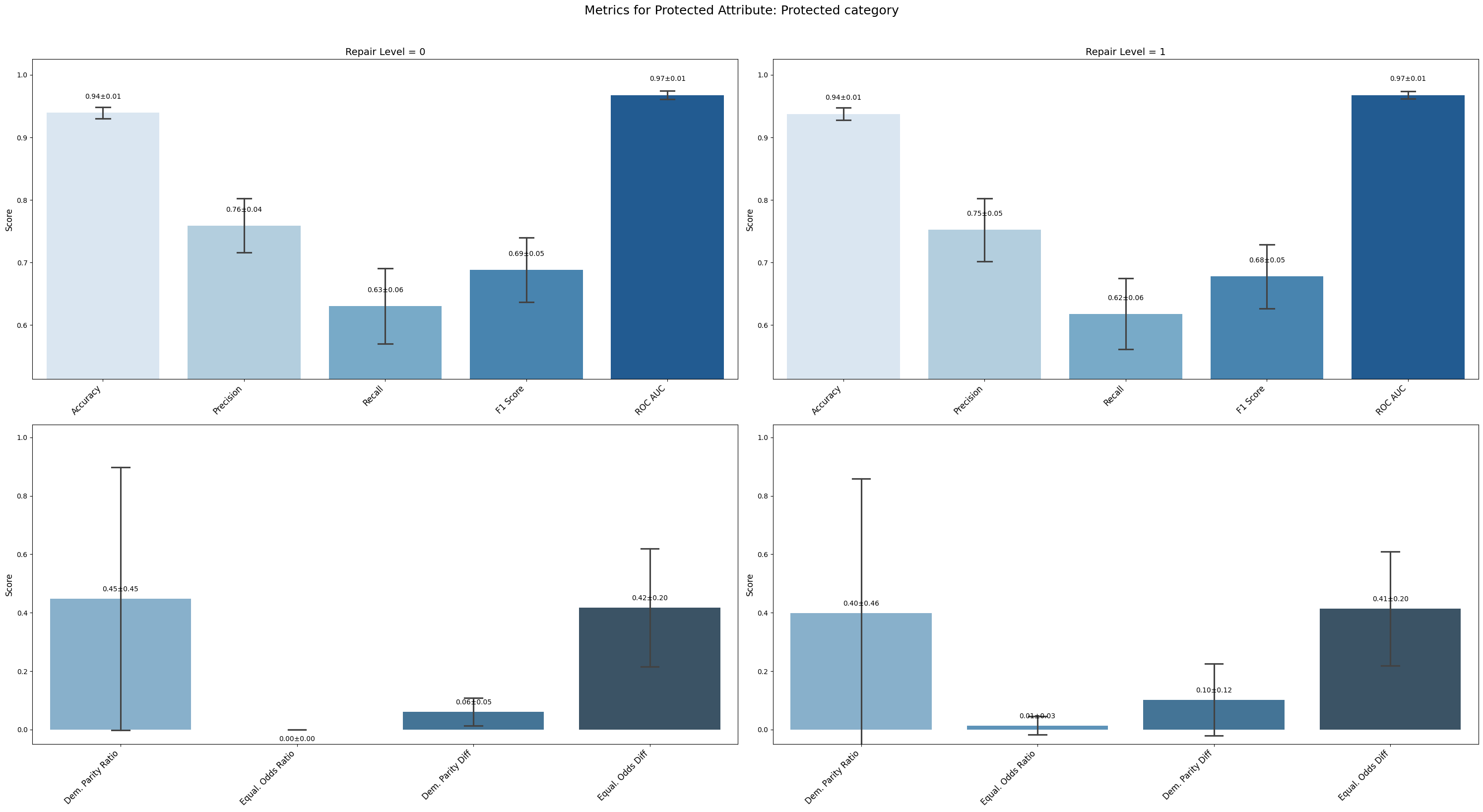
=== Results for sensitive attribute: Protected category ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.938 ± 0.009
precision 0.759 ± 0.039 0.752 ± 0.045
recall 0.631 ± 0.054 0.618 ± 0.051
f1 0.688 ± 0.046 0.678 ± 0.046
roc_auc 0.968 ± 0.006 0.968 ± 0.005
demographic_parity_ratio 0.448 ± 0.402 0.399 ± 0.411
equalized_odds_ratio 0.000 ± 0.000 0.014 ± 0.028
demographic_parity_difference 0.061 ± 0.042 0.102 ± 0.110
equalized_odds_difference 0.418 ± 0.181 0.414 ± 0.175
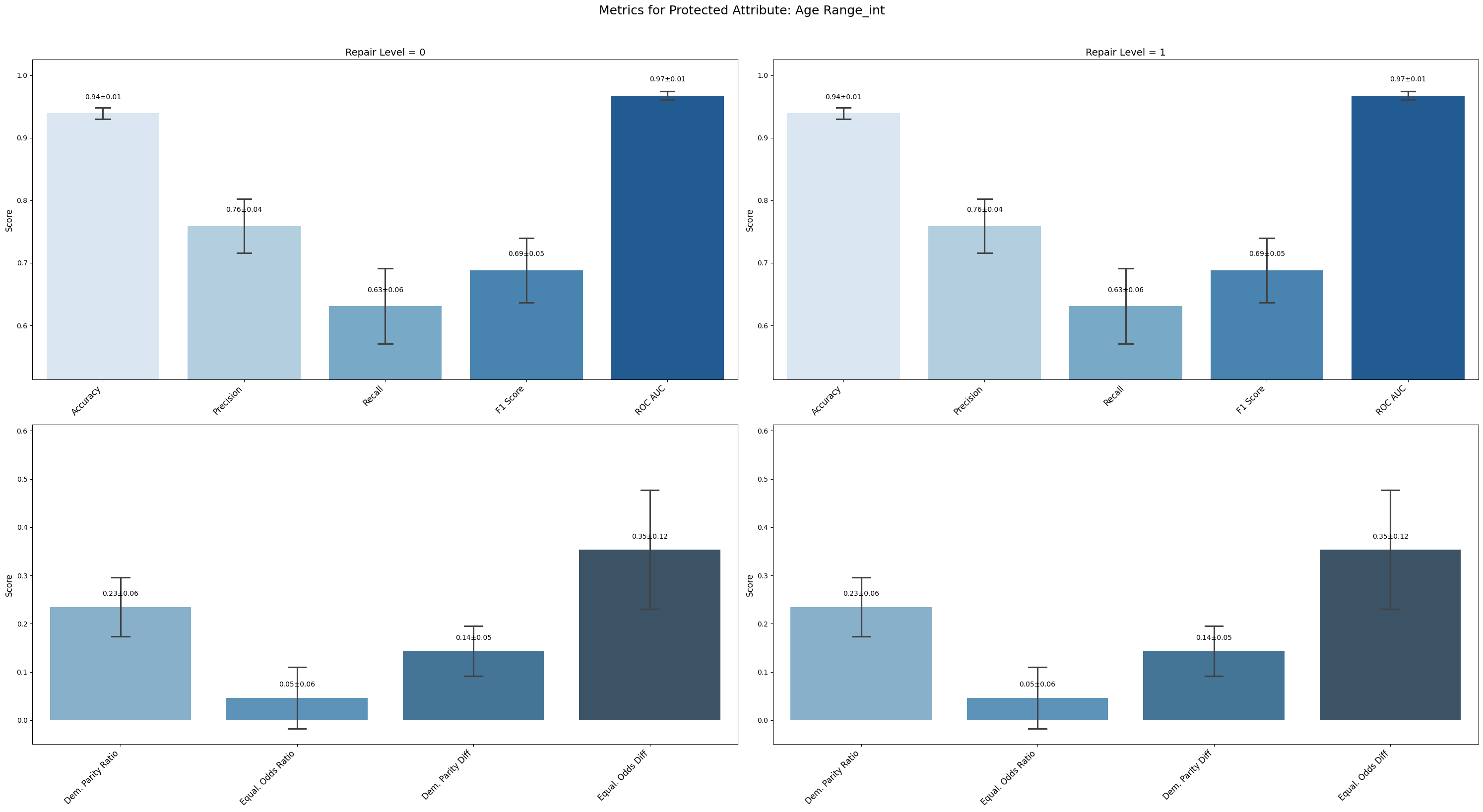
=== Results for sensitive attribute: Age Range_int ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.939 ± 0.008
precision 0.759 ± 0.039 0.759 ± 0.039
recall 0.631 ± 0.054 0.631 ± 0.054
f1 0.688 ± 0.046 0.688 ± 0.046
roc_auc 0.968 ± 0.006 0.968 ± 0.006
demographic_parity_ratio 0.235 ± 0.055 0.235 ± 0.055
equalized_odds_ratio 0.047 ± 0.057 0.047 ± 0.057
demographic_parity_difference 0.143 ± 0.046 0.143 ± 0.046
equalized_odds_difference 0.354 ± 0.110 0.354 ± 0.110
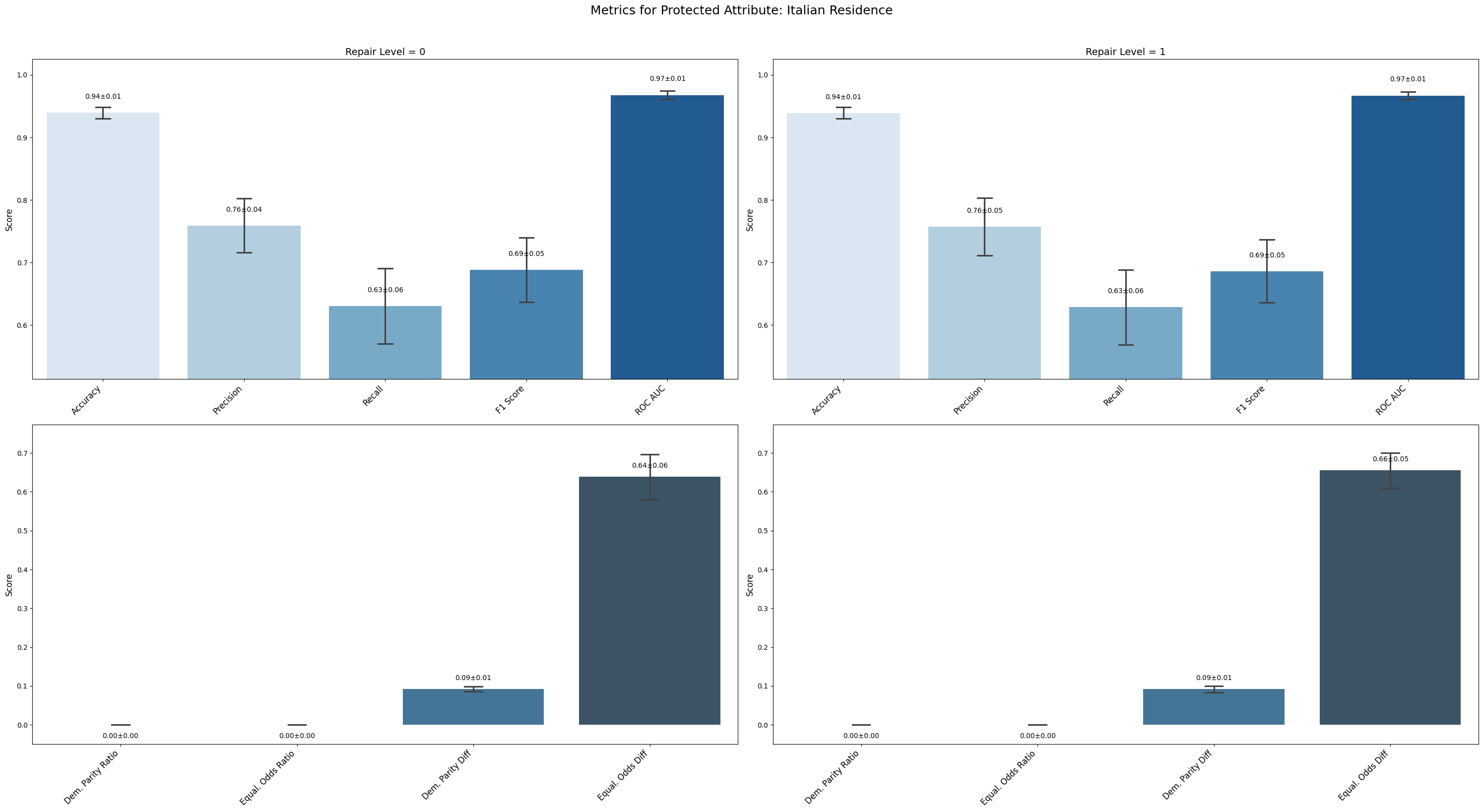
=== Results for sensitive attribute: Italian Residence ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.939 ± 0.008
precision 0.759 ± 0.039 0.757 ± 0.041
recall 0.631 ± 0.054 0.629 ± 0.053
f1 0.688 ± 0.046 0.686 ± 0.045
roc_auc 0.968 ± 0.006 0.967 ± 0.006
demographic_parity_ratio 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.092 ± 0.006 0.092 ± 0.007
equalized_odds_difference 0.638 ± 0.052 0.655 ± 0.040
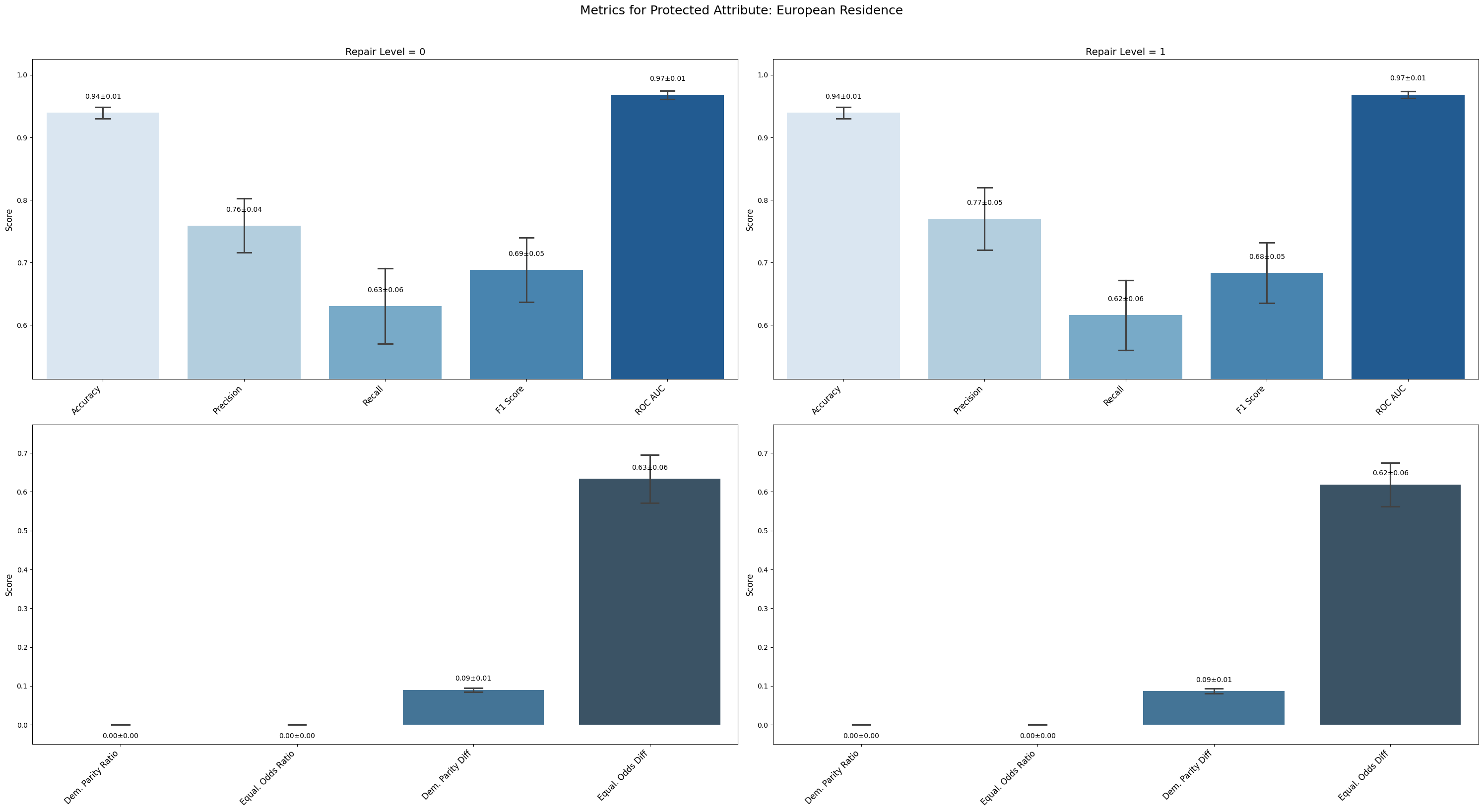
=== Results for sensitive attribute: European Residence ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.939 ± 0.008
precision 0.759 ± 0.039 0.770 ± 0.045
recall 0.631 ± 0.054 0.616 ± 0.050
f1 0.688 ± 0.046 0.684 ± 0.043
roc_auc 0.968 ± 0.006 0.969 ± 0.005
demographic_parity_ratio 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.090 ± 0.005 0.087 ± 0.005
equalized_odds_difference 0.633 ± 0.055 0.618 ± 0.050
=== Results for sensitive attribute: all ===
Repair 0 Repair 1
accuracy 0.939 ± 0.008 0.938 ± 0.007
precision 0.759 ± 0.039 0.759 ± 0.034
recall 0.631 ± 0.054 0.616 ± 0.055
f1 0.688 ± 0.046 0.679 ± 0.044
roc_auc 0.968 ± 0.006 0.968 ± 0.005
demographic_parity_ratio 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.767 ± 0.291 0.767 ± 0.291
equalized_odds_difference 1.000 ± 0.000 1.000 ± 0.000
for metric in ['accuracy', 'f1', 'roc_auc', 'demographic_parity_ratio', 'equalized_odds_ratio']:
plot_metrics(plot_data, metric, repair_levels, combined_protected_attributes)
plot_metrics_grouped(results, combined_protected_attributes, repair_levels)
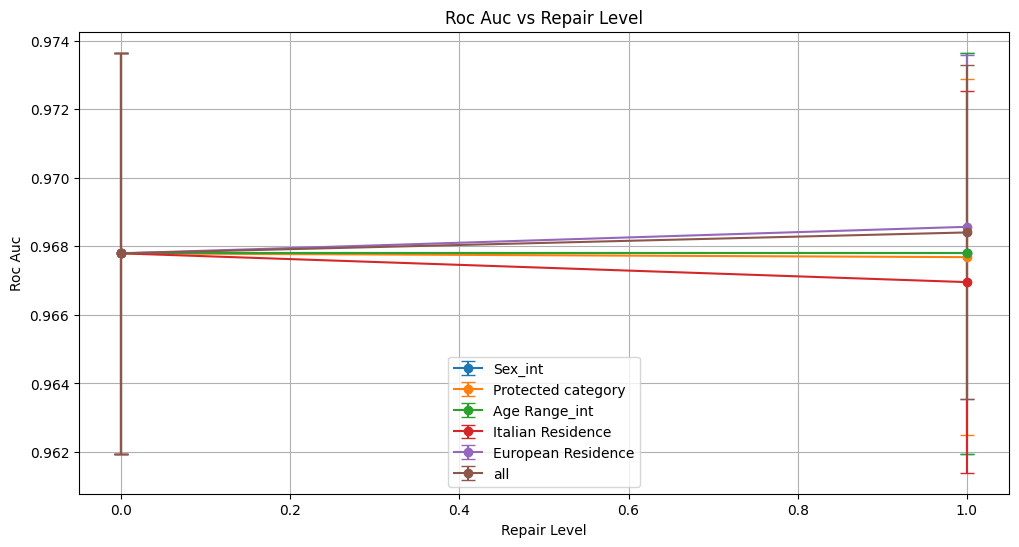
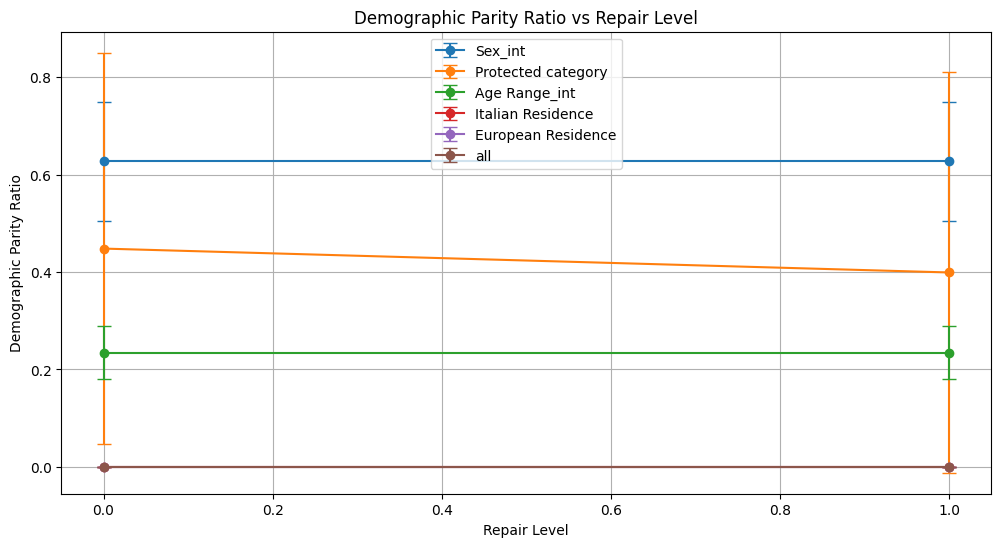
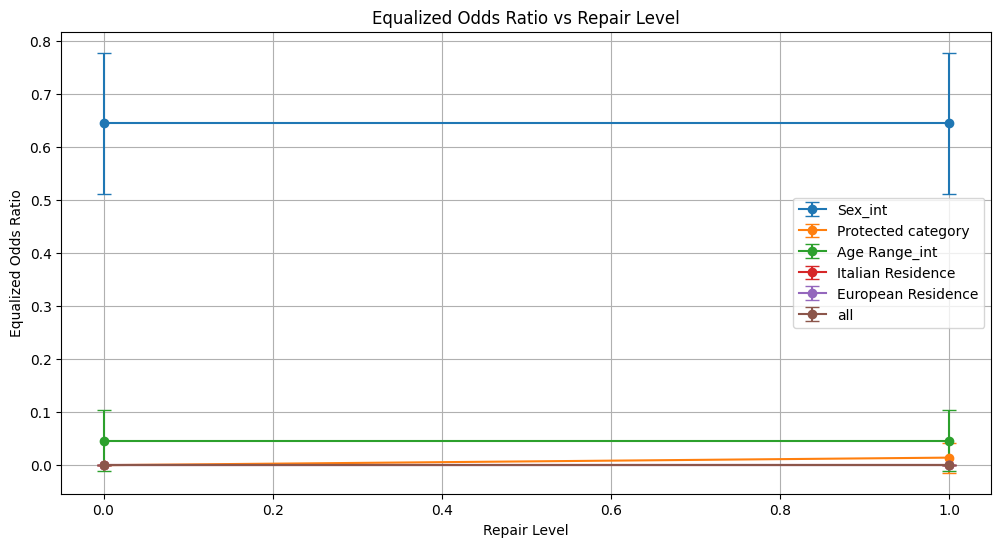
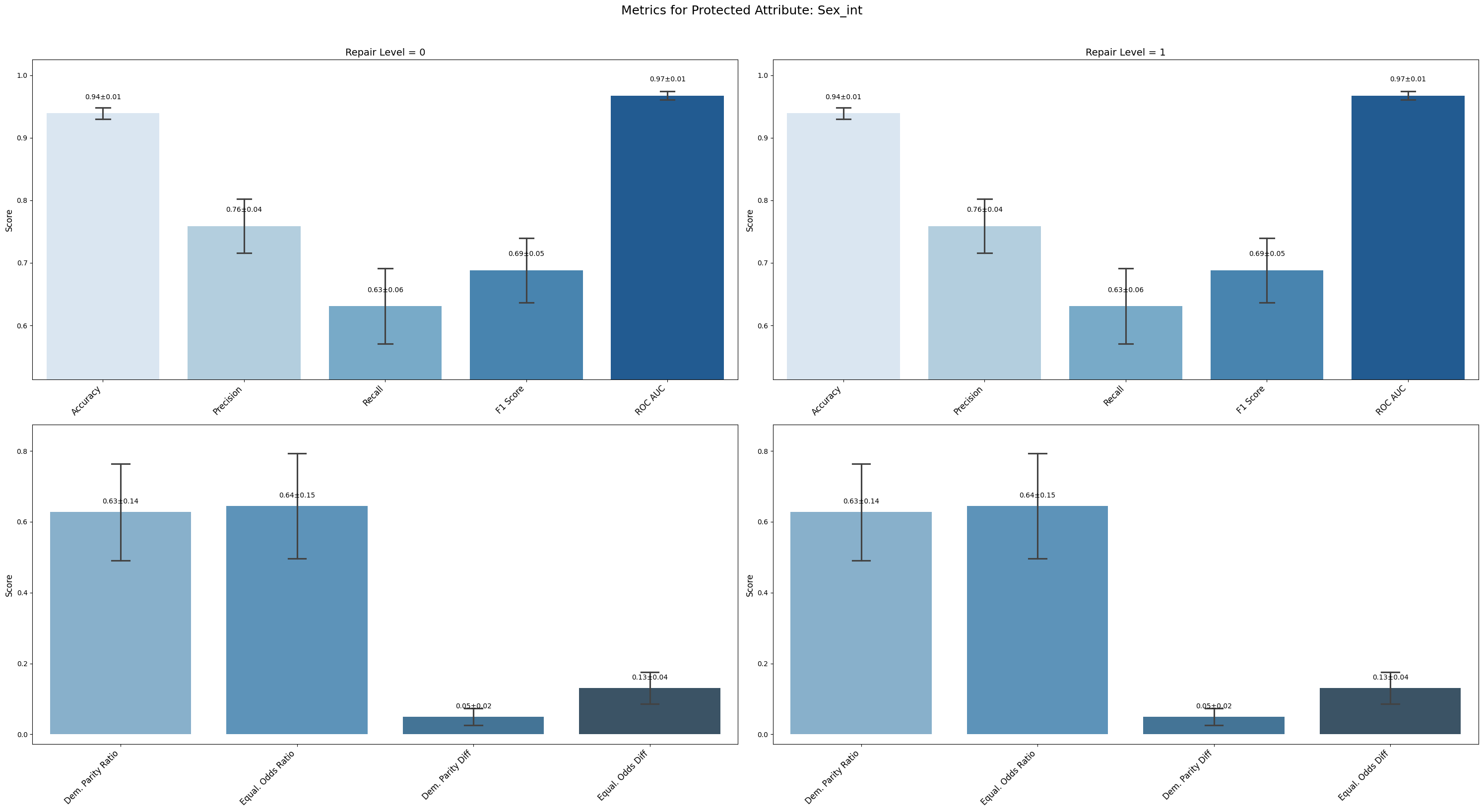
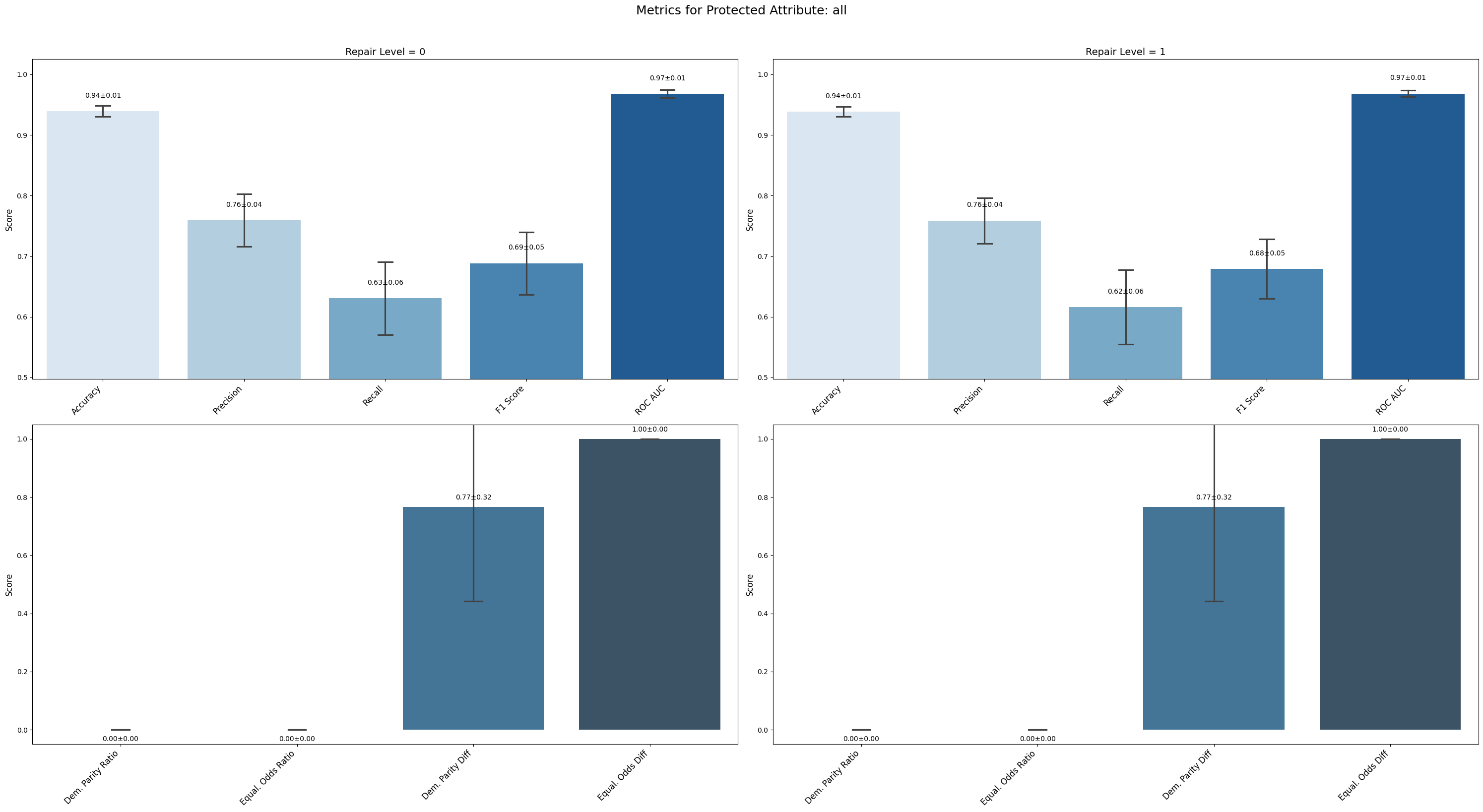
Conclusion on Reweighing Technique
The Reweighing technique was evaluated across several sensitive attributes (Sex, Protected Category, Age Range, Italian Residence, European Residence, and All Combined), comparing results before and after applying the method (Repair 0 vs Repair 1).
Model Performance:
Reweighing had a negligible impact on overall predictive performance. Accuracy, precision, recall, F1 score, and ROC AUC remained essentially unchanged across all sensitive attributes, indicating the model’s predictive ability was preserved.
Bias Mitigation:
For Sex_int, fairness metrics such as demographic parity and equalized odds ratios remained stable, showing no meaningful improvement.
Protected Category and Age Range_int experienced minimal to no reductions in fairness disparities. In fact, some fairness indicators (e.g., demographic parity difference for Protected Category) slightly worsened.
Italian Residence and European Residence attributes showed no improvement; demographic parity and equalized odds ratios stayed at zero, indicating persistent and unmitigated bias.
When assessing all attributes combined, fairness metrics remained at extreme levels without improvement, highlighting the technique’s inability to reduce compounded bias effects.
Conclusion: While the reweighing method successfully preserves model performance, its effectiveness in reducing bias is limited. Particularly for geographic attributes and compounded bias scenarios, reweighing shows little to no impact. This suggests it may be insufficient as a standalone fairness intervention and would benefit from integration with more advanced or complementary bias mitigation strategies.