Inprocessing Bias Mitigation Techniques
Load Data
import sys
import os
# Add the root directory of the project to PYTHONPATH
sys.path.append(os.path.abspath(os.path.join('../../master-thesis-dizio-ay2324')))
from collections import defaultdict
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.model_selection import StratifiedKFold
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import (
accuracy_score, precision_score, recall_score,
f1_score, roc_auc_score
)
from fairlearn.metrics import (
demographic_parity_ratio,
equalized_odds_ratio,
demographic_parity_difference,
equalized_odds_difference
)
from fairlib.inprocessing.prejudice_remover import PrejudiceRemover
from fairlib.inprocessing.fauci import Fauci
from fairlib.dataframe import DataFrame
import torch.nn as nn
from utils.plot import plot_metrics, plot_metrics_grouped, get_mean_std, print_fairness_results_table
random_state = 42
np.random.seed(random_state)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 22
9 from sklearn.metrics import (
10 accuracy_score, precision_score, recall_score,
11 f1_score, roc_auc_score
12 )
15 from fairlearn.metrics import (
16 demographic_parity_ratio,
17 equalized_odds_ratio,
18 demographic_parity_difference,
19 equalized_odds_difference
20 )
---> 22 from fairlib.inprocessing.prejudice_remover import PrejudiceRemover
23 from fairlib.inprocessing.fauci import Fauci
24 from fairlib.dataframe import DataFrame
ModuleNotFoundError: No module named 'fairlib'
df_cleaned = pd.read_csv('cleaned_dataset.csv')
features = [
# Base Attributes
"Sex_int",
"Protected category",
"Overall",
"Technical Skills",
"Standing/Position",
"Comunication",
"Maturity",
"Dynamism",
"Mobility",
"English",
"Italian Residence",
"European Residence",
"Age Range_int",
"number_of_searches",
# Custom Similarity Scores
"experience_match_score",
"current_salary_fit_score",
"expected_salary_fit_score",
"study_title_score",
"professional_similarity_score",
"study_area_score",
"general_similarity_score",
"Distance Residence - Akkodis HQ",
"Distance Residence - Assumption HQ",
]
protected_attributes = [
'Sex_int', 'Protected category', 'Age Range_int',
'Italian Residence', 'European Residence'
]
n_folds = 5
dataset = pd.DataFrame(df_cleaned[features + ['Hired']])
bool_cols = dataset.select_dtypes(include='bool').columns
non_bool_cols = dataset[features].columns.difference(bool_cols)
dataset[bool_cols] = dataset[bool_cols].astype(int)
repair_levels = [0, 0.5, 1]
kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42)
Base Model
base_model_lambda = lambda: nn.Sequential(
nn.Linear(len(features), 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
Fauci
results = defaultdict(list)
plot_data = defaultdict(dict)
for fold, (train_idx, test_idx) in tqdm(enumerate(kf.split(dataset, dataset['Hired'])), total=n_folds, desc='Folds...'):
train_df = dataset.iloc[train_idx].copy()
test_df = dataset.iloc[test_idx].copy()
imputer = SimpleImputer(strategy='mean')
train_df = pd.DataFrame(imputer.fit_transform(train_df), columns=train_df.columns)
test_df = pd.DataFrame(imputer.transform(test_df), columns=test_df.columns)
train_df = DataFrame(train_df)
test_df = DataFrame(test_df)
scaler = StandardScaler()
train_df[non_bool_cols] = scaler.fit_transform(train_df[non_bool_cols])
test_df[non_bool_cols] = scaler.transform(test_df[non_bool_cols])
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
train_df.sensitive = sensitive_attr
train_df.targets = 'Hired'
test_df.sensitive = sensitive_attr
test_df.targets = 'Hired'
base_model = base_model_lambda()
model = Fauci(
torchModel=base_model,
weight=repair_level
)
model.fit(train_df[features], train_df[['Hired']], num_epochs=20, batch_size=32)
train_probs = model.predict(train_df[features]).numpy()
thresholds = np.linspace(0, 1, 101)
best_threshold = 0.5
best_f1 = 0.0
y_train_true = train_df[['Hired']].values
for thresh in thresholds:
train_preds = (train_probs > thresh).astype(int)
f1 = f1_score(y_train_true, train_preds, zero_division=0)
if f1 > best_f1:
best_f1 = f1
best_threshold = thresh
y_pred = model.predict(test_df[features])
y_prob = y_pred.numpy()
y_pred_binary = (y_prob > best_threshold).astype(int)
y_test = test_df[['Hired']].values
metrics = {
'accuracy': accuracy_score(y_test, y_pred_binary),
'precision': precision_score(y_test, y_pred_binary, zero_division=0),
'recall': recall_score(y_test, y_pred_binary, zero_division=0),
'f1': f1_score(y_test, y_pred_binary, zero_division=0),
'roc_auc': roc_auc_score(y_test, y_prob),
'demographic_parity_ratio': demographic_parity_ratio(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'equalized_odds_ratio': equalized_odds_ratio(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'demographic_parity_difference': demographic_parity_difference(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'equalized_odds_difference': equalized_odds_difference(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
}
key = f"{sensitive_attr}_repair_{repair_level}"
results[key].append(metrics)
metrics_keys = list(metrics.keys())
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
key = f"{sensitive_attr}_repair_{repair_level}"
fold_metrics = results.get(key, [])
for metric in metrics_keys:
metric_list = [m[metric] for m in fold_metrics]
mean, std = get_mean_std(metric_list)
plot_data[sensitive_attr][f"{metric}_mean_{repair_level}"] = mean
plot_data[sensitive_attr][f"{metric}_std_{repair_level}"] = std
Folds...: 100%|██████████| 5/5 [27:53<00:00, 334.66s/it]
print_fairness_results_table(plot_data, metrics_keys, repair_levels)
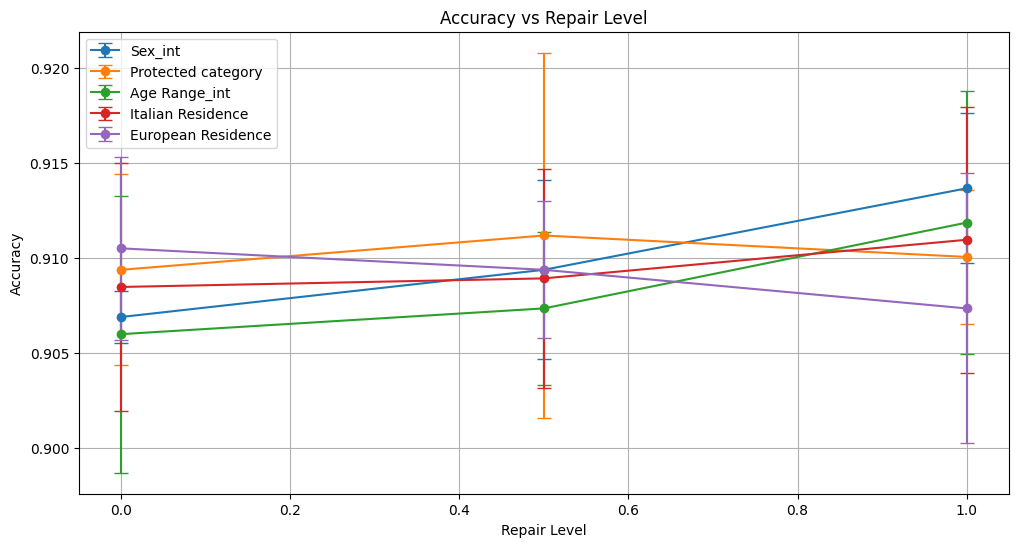
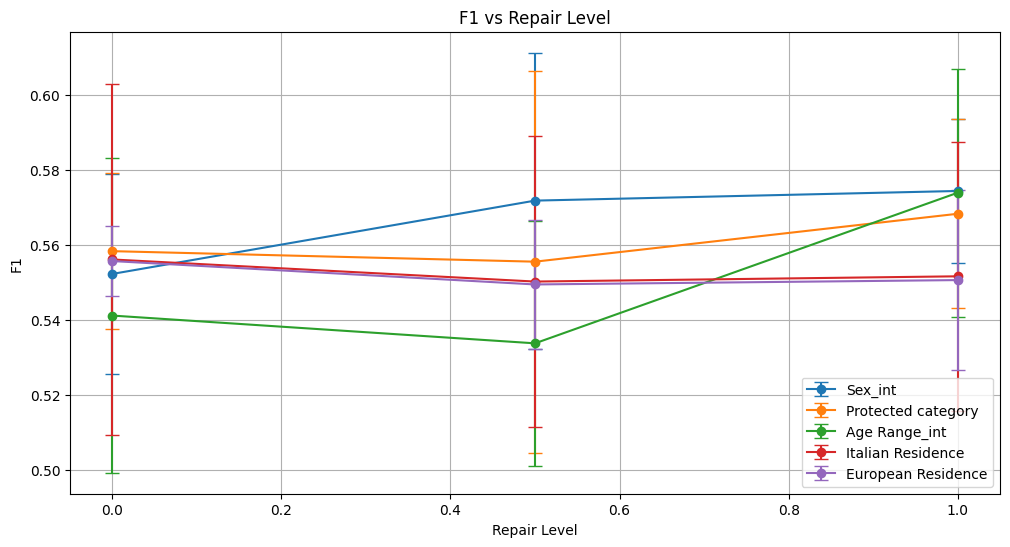
=== Results for sensitive attribute: Sex_int ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.910 ± 0.007 0.913 ± 0.007 0.911 ± 0.007
precision 0.586 ± 0.026 0.615 ± 0.041 0.596 ± 0.041
recall 0.510 ± 0.106 0.503 ± 0.056 0.510 ± 0.053
f1 0.540 ± 0.066 0.552 ± 0.042 0.548 ± 0.040
roc_auc 0.865 ± 0.029 0.854 ± 0.038 0.844 ± 0.034
demographic_parity_ratio 0.629 ± 0.148 0.642 ± 0.099 0.627 ± 0.107
equalized_odds_ratio 0.651 ± 0.113 0.620 ± 0.095 0.627 ± 0.171
demographic_parity_difference 0.051 ± 0.023 0.046 ± 0.019 0.052 ± 0.024
equalized_odds_difference 0.152 ± 0.098 0.161 ± 0.071 0.089 ± 0.053
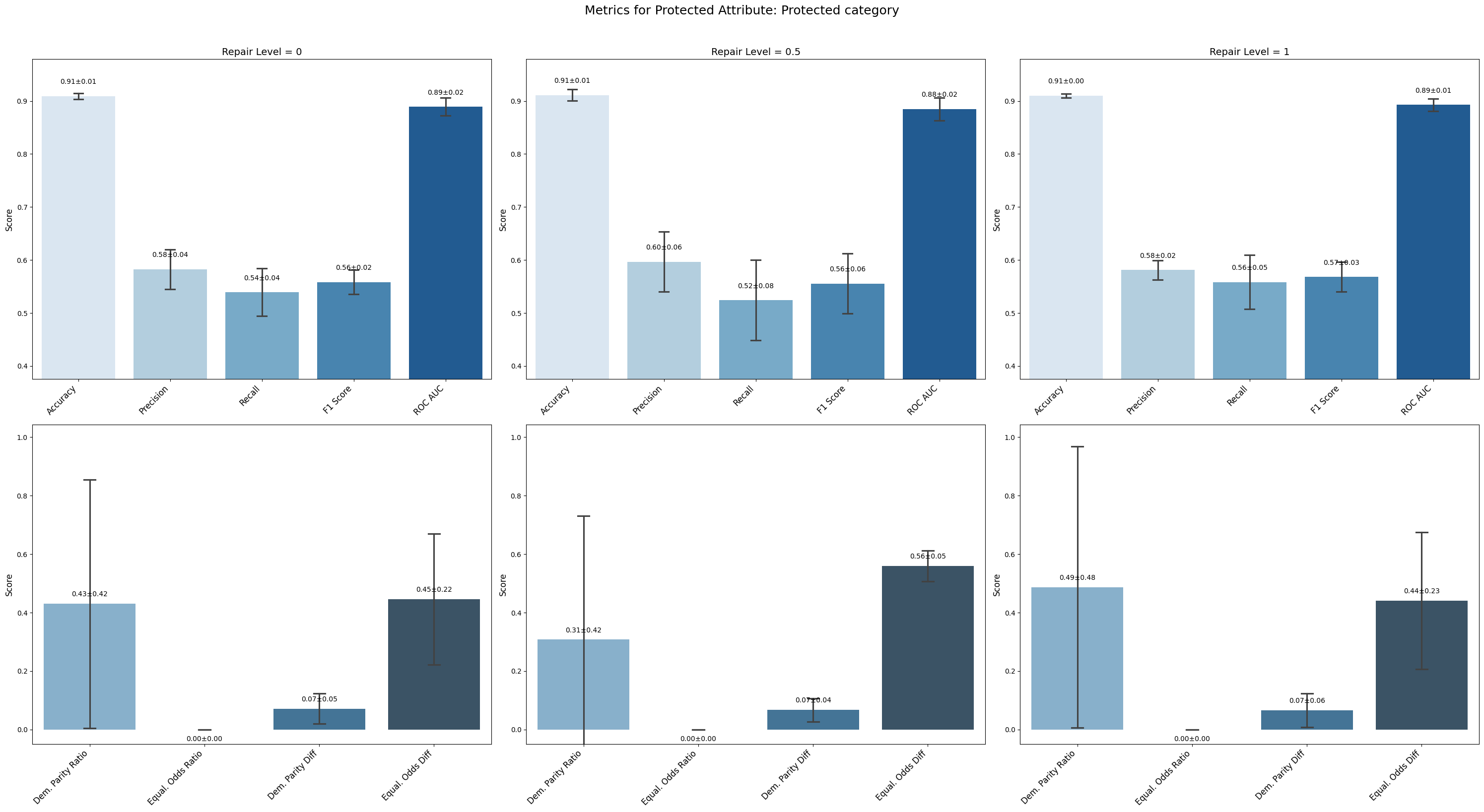
=== Results for sensitive attribute: Protected category ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.106 ± 0.000 0.106 ± 0.000 0.106 ± 0.000
precision 0.106 ± 0.000 0.106 ± 0.000 0.106 ± 0.000
recall 1.000 ± 0.000 1.000 ± 0.000 1.000 ± 0.000
f1 0.192 ± 0.001 0.192 ± 0.001 0.192 ± 0.001
roc_auc 0.325 ± 0.036 0.327 ± 0.040 0.332 ± 0.028
demographic_parity_ratio 1.000 ± 0.000 1.000 ± 0.000 1.000 ± 0.000
equalized_odds_ratio 0.600 ± 0.490 0.600 ± 0.490 0.600 ± 0.490
demographic_parity_difference 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_difference 0.400 ± 0.490 0.400 ± 0.490 0.400 ± 0.490
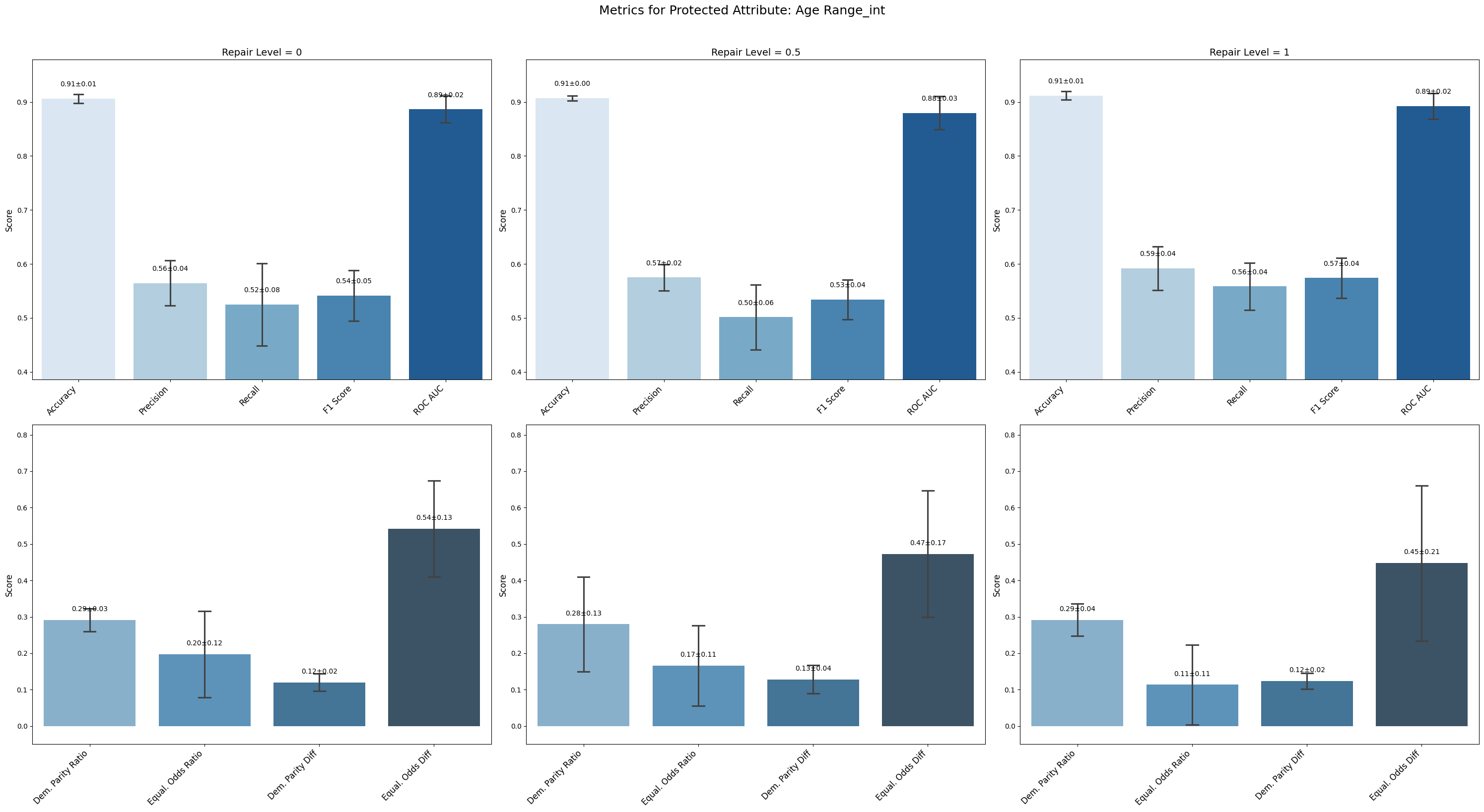
=== Results for sensitive attribute: Age Range_int ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.912 ± 0.006 0.908 ± 0.004 0.907 ± 0.010
precision 0.603 ± 0.034 0.575 ± 0.024 0.571 ± 0.053
recall 0.510 ± 0.049 0.507 ± 0.046 0.501 ± 0.065
f1 0.552 ± 0.038 0.538 ± 0.030 0.533 ± 0.057
roc_auc 0.853 ± 0.023 0.867 ± 0.023 0.865 ± 0.028
demographic_parity_ratio 0.182 ± 0.090 0.184 ± 0.050 0.330 ± 0.121
equalized_odds_ratio 0.118 ± 0.108 0.131 ± 0.109 0.204 ± 0.128
demographic_parity_difference 0.164 ± 0.058 0.148 ± 0.032 0.107 ± 0.030
equalized_odds_difference 0.619 ± 0.122 0.598 ± 0.062 0.486 ± 0.106
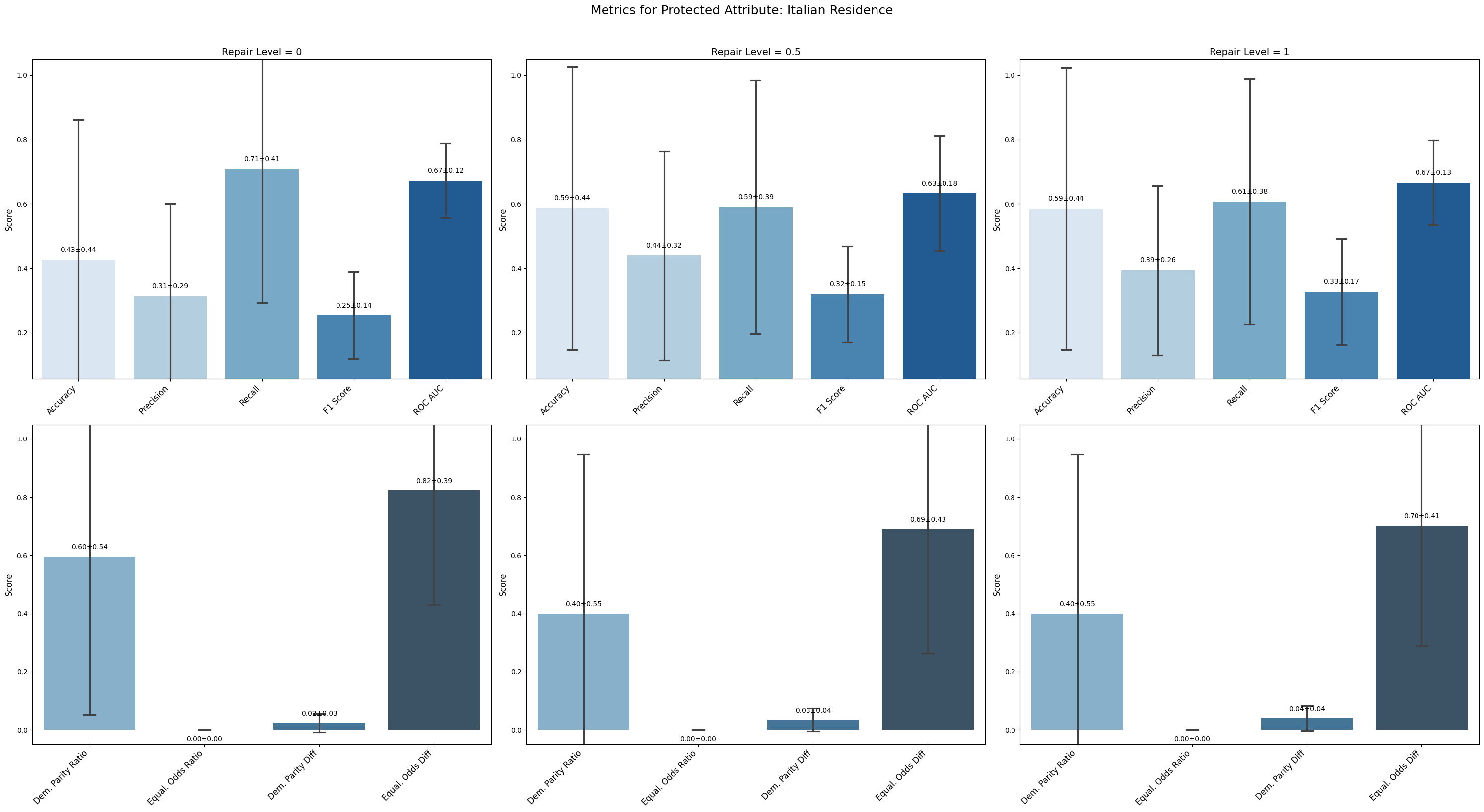
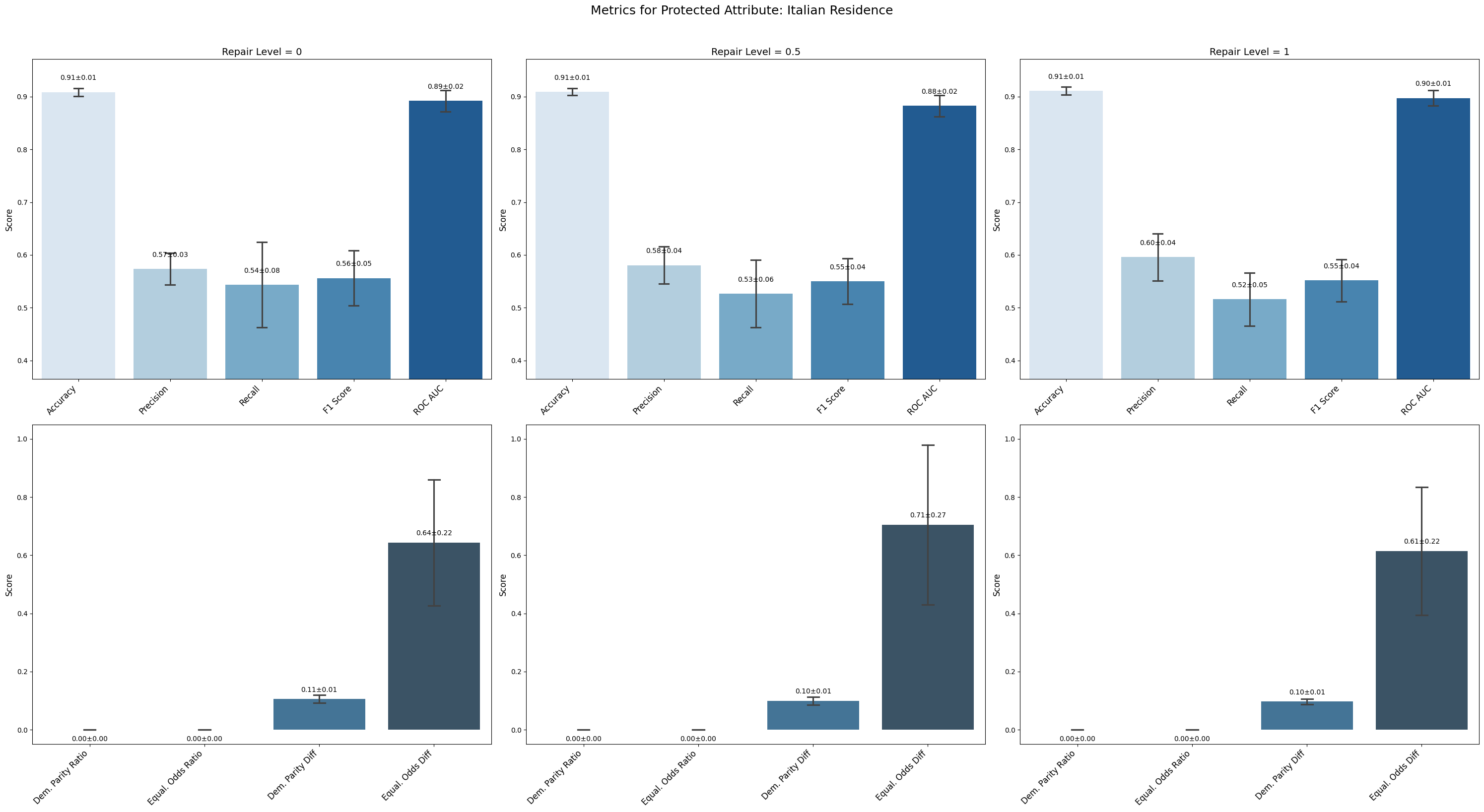
=== Results for sensitive attribute: Italian Residence ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.426 ± 0.390 0.587 ± 0.393 0.586 ± 0.391
precision 0.314 ± 0.255 0.440 ± 0.290 0.394 ± 0.236
recall 0.708 ± 0.371 0.590 ± 0.352 0.607 ± 0.341
f1 0.254 ± 0.121 0.320 ± 0.134 0.328 ± 0.148
roc_auc 0.673 ± 0.103 0.633 ± 0.160 0.667 ± 0.117
demographic_parity_ratio 0.596 ± 0.487 0.400 ± 0.490 0.400 ± 0.490
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.023 ± 0.028 0.034 ± 0.035 0.039 ± 0.038
equalized_odds_difference 0.824 ± 0.353 0.689 ± 0.381 0.702 ± 0.369
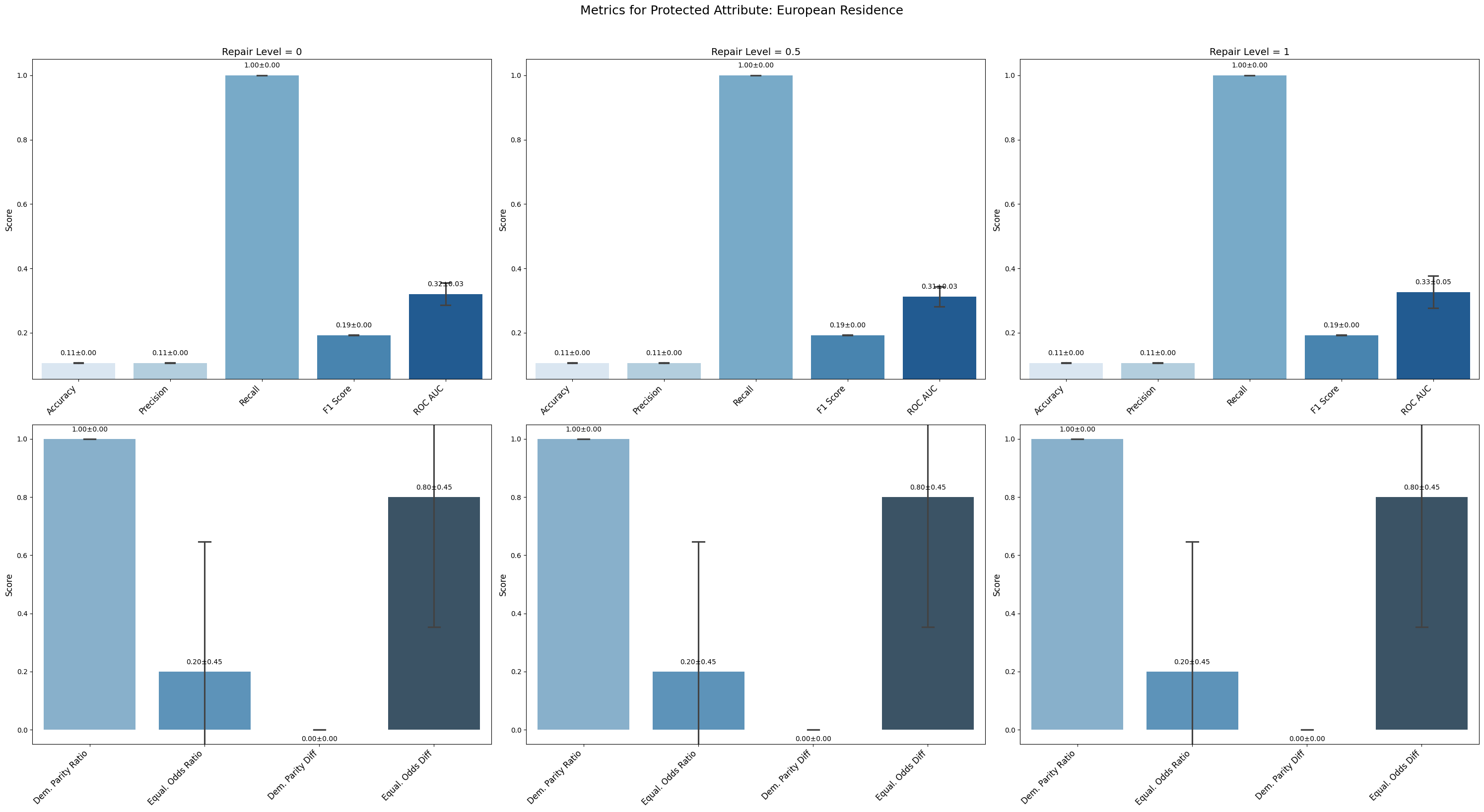
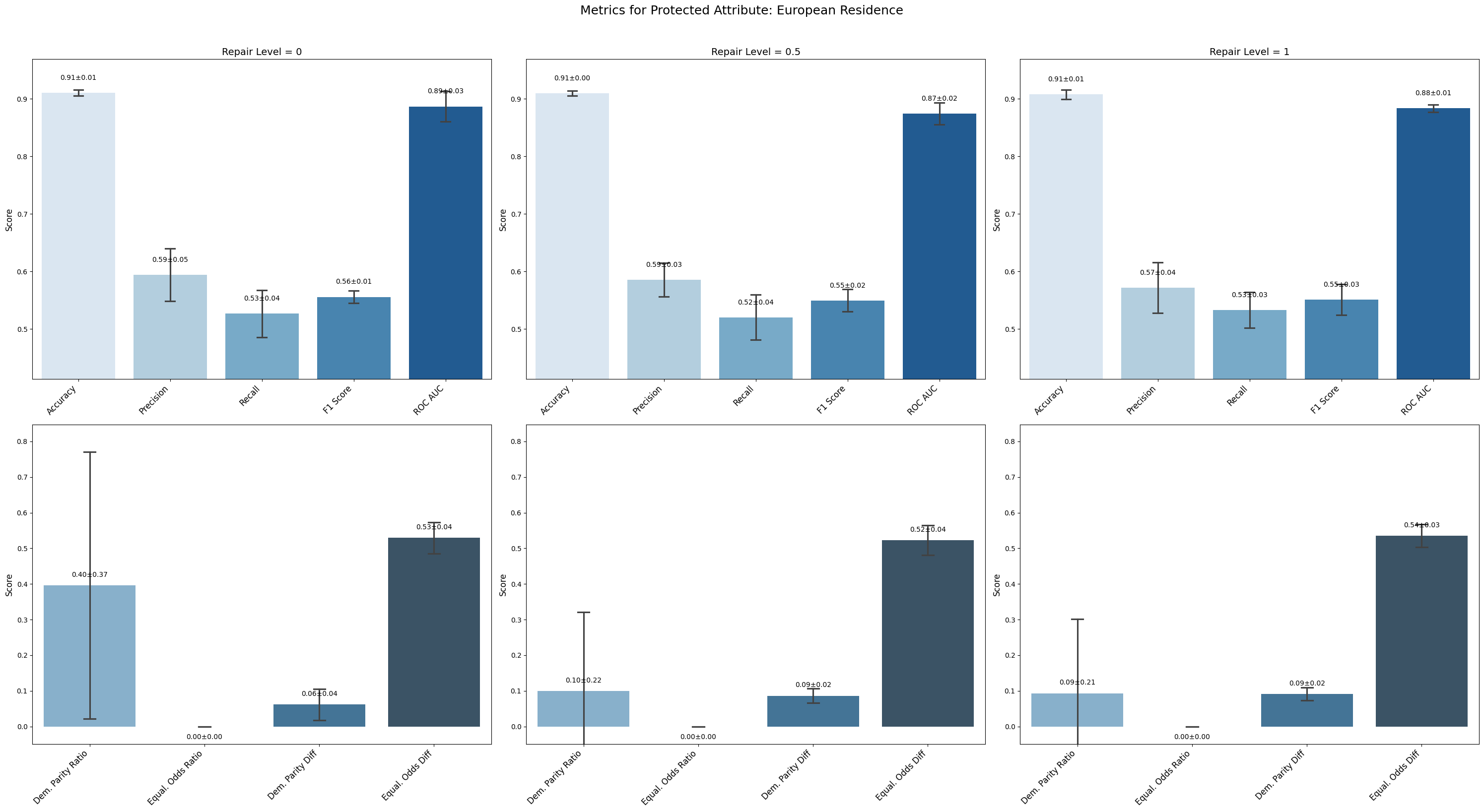
=== Results for sensitive attribute: European Residence ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.106 ± 0.000 0.106 ± 0.000 0.106 ± 0.000
precision 0.106 ± 0.000 0.106 ± 0.000 0.106 ± 0.000
recall 1.000 ± 0.000 1.000 ± 0.000 1.000 ± 0.000
f1 0.192 ± 0.001 0.192 ± 0.001 0.192 ± 0.001
roc_auc 0.320 ± 0.031 0.312 ± 0.028 0.326 ± 0.045
demographic_parity_ratio 1.000 ± 0.000 1.000 ± 0.000 1.000 ± 0.000
equalized_odds_ratio 0.200 ± 0.400 0.200 ± 0.400 0.200 ± 0.400
demographic_parity_difference 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_difference 0.800 ± 0.400 0.800 ± 0.400 0.800 ± 0.400
for metric in ['accuracy', 'f1', 'roc_auc', 'demographic_parity_ratio', 'equalized_odds_ratio']:
plot_metrics(plot_data, metric, repair_levels, protected_attributes)
plot_metrics_grouped(results,
protected_attributes=protected_attributes,
repair_levels=repair_levels)
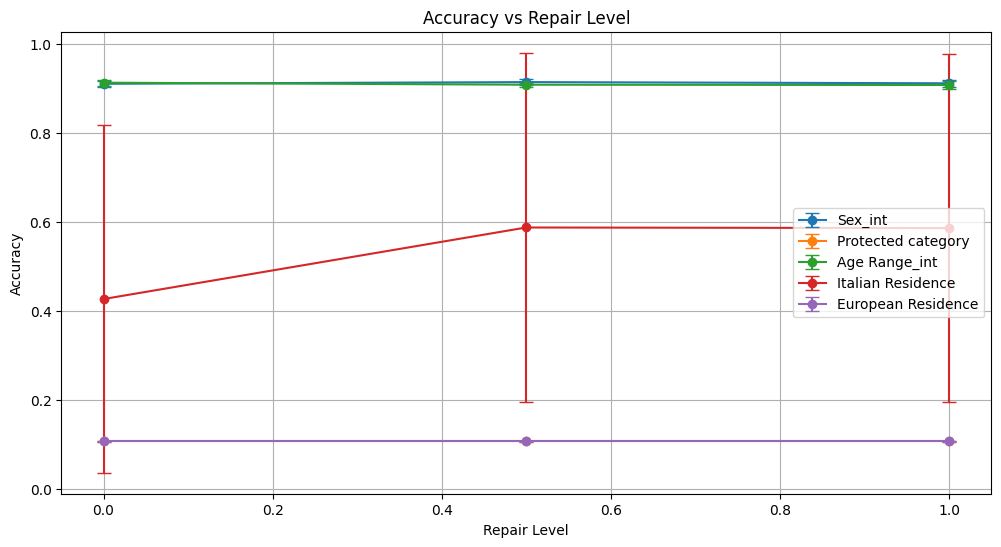
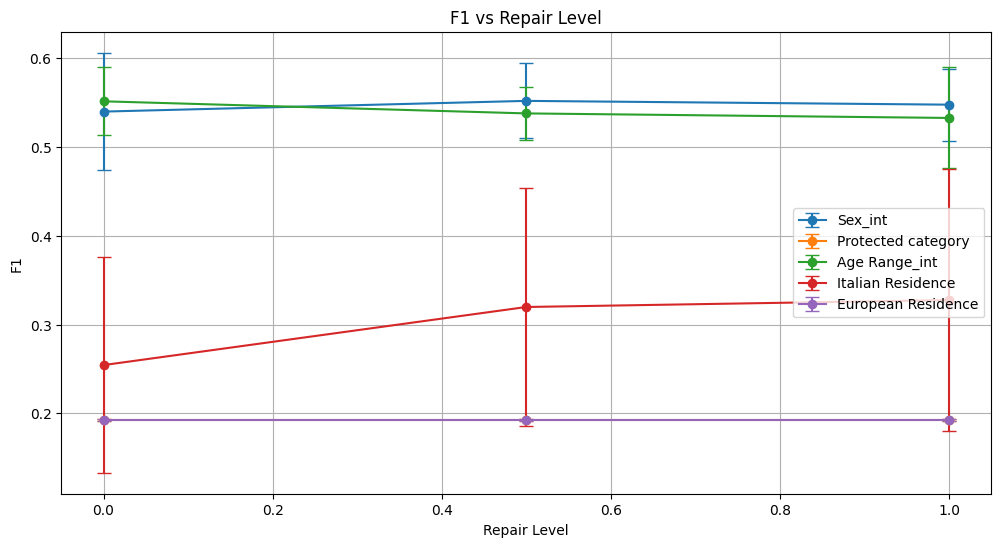
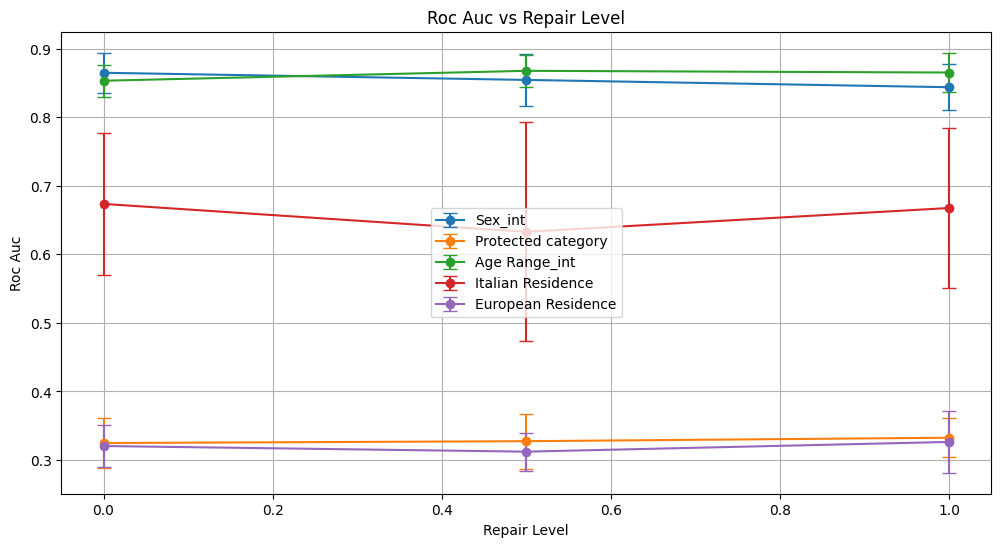
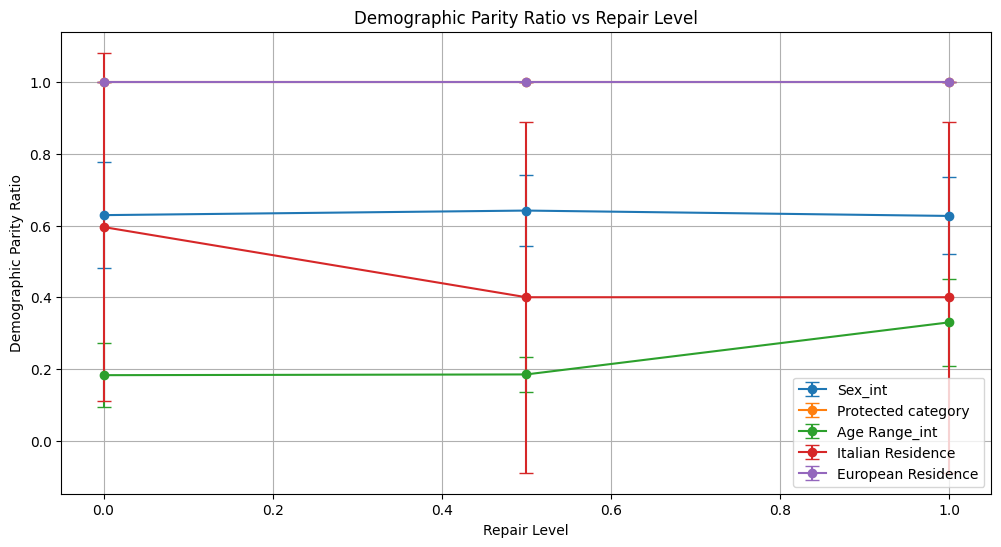
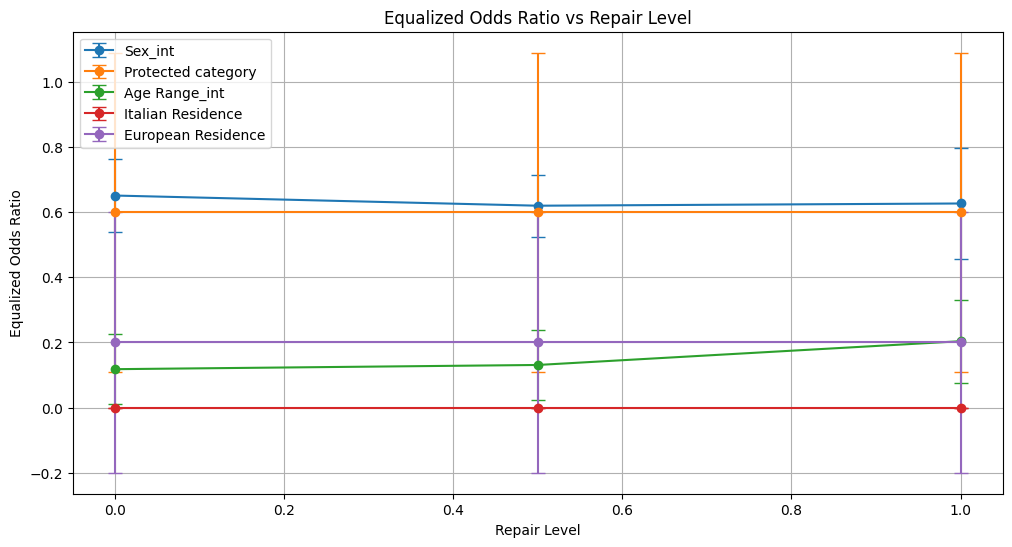
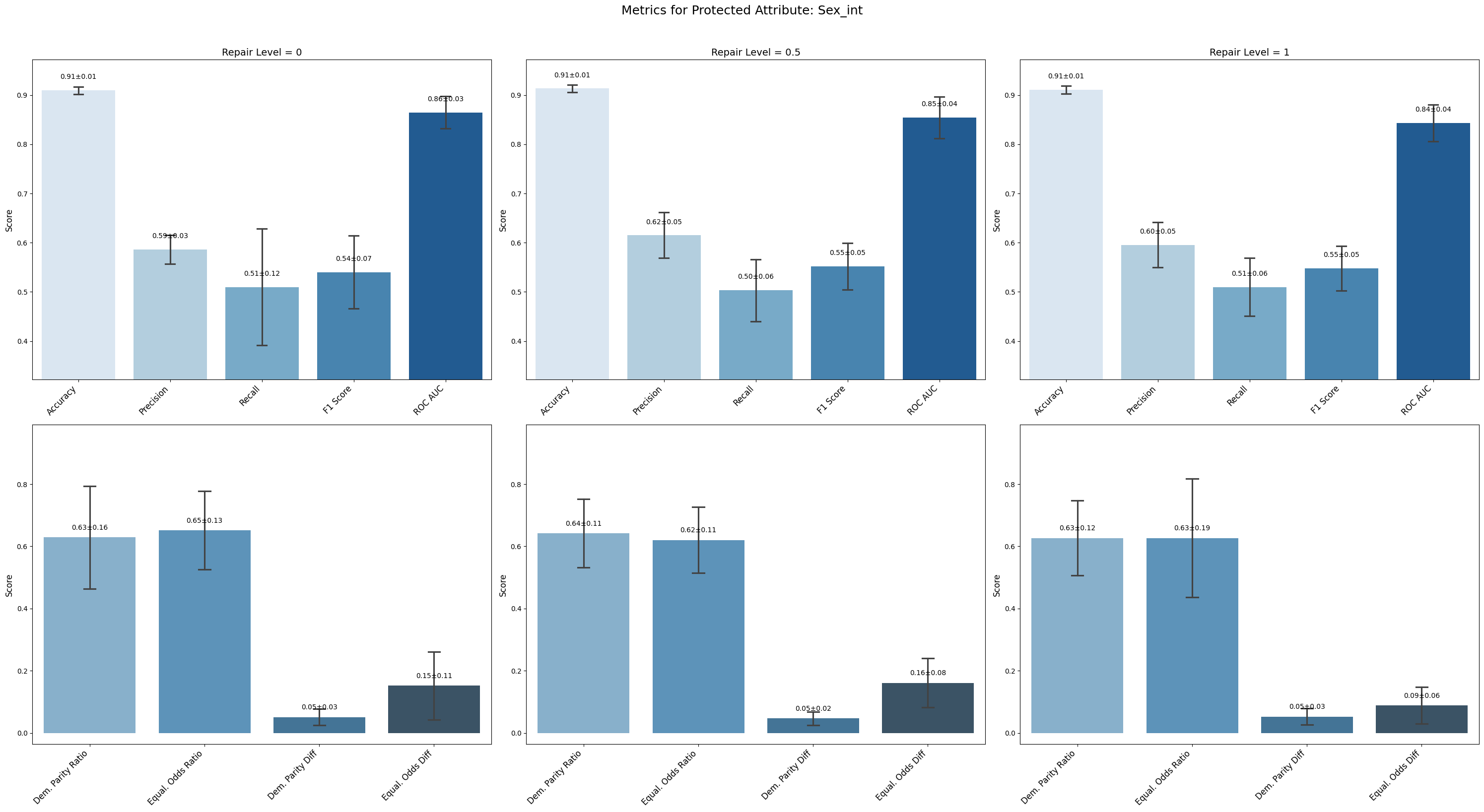
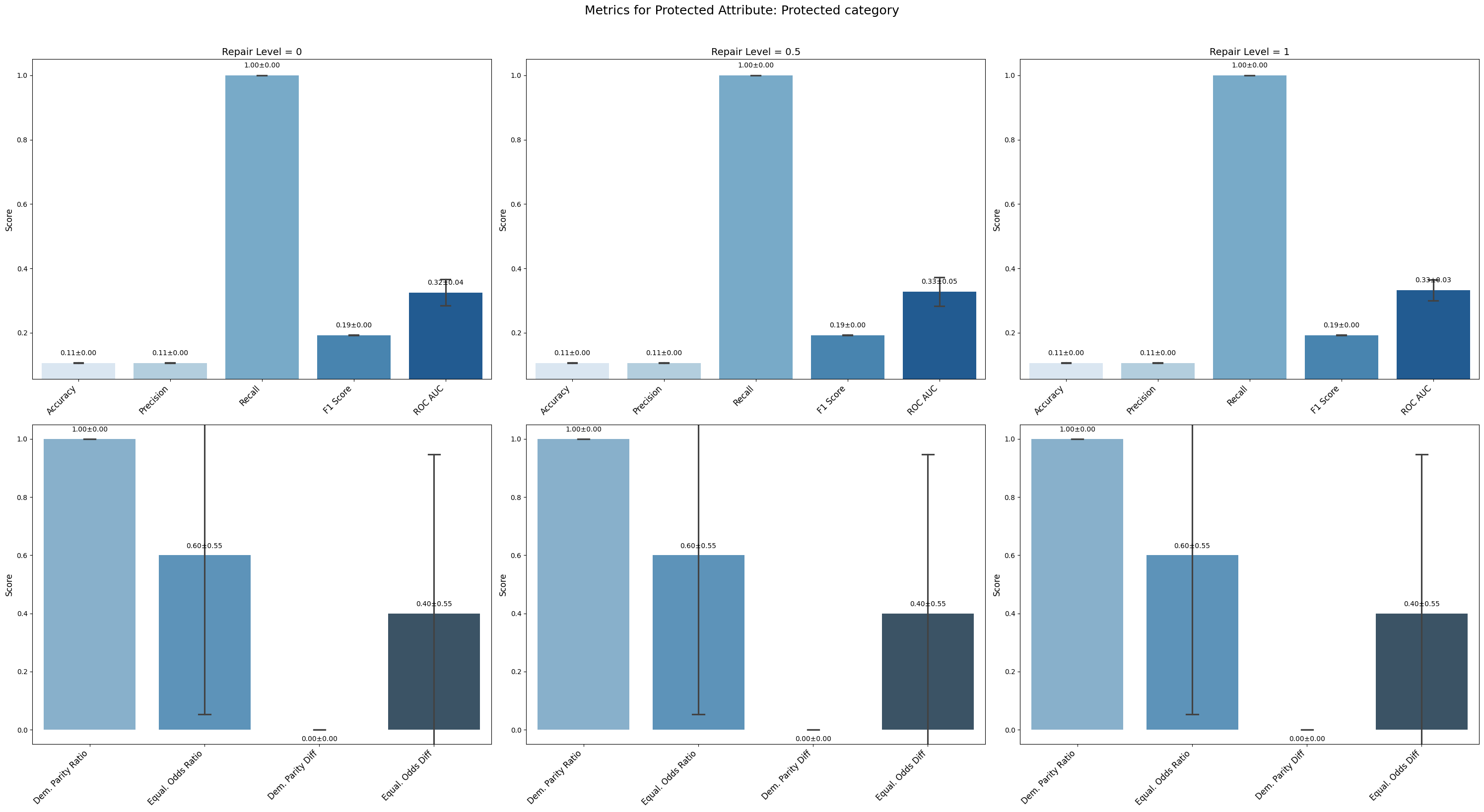
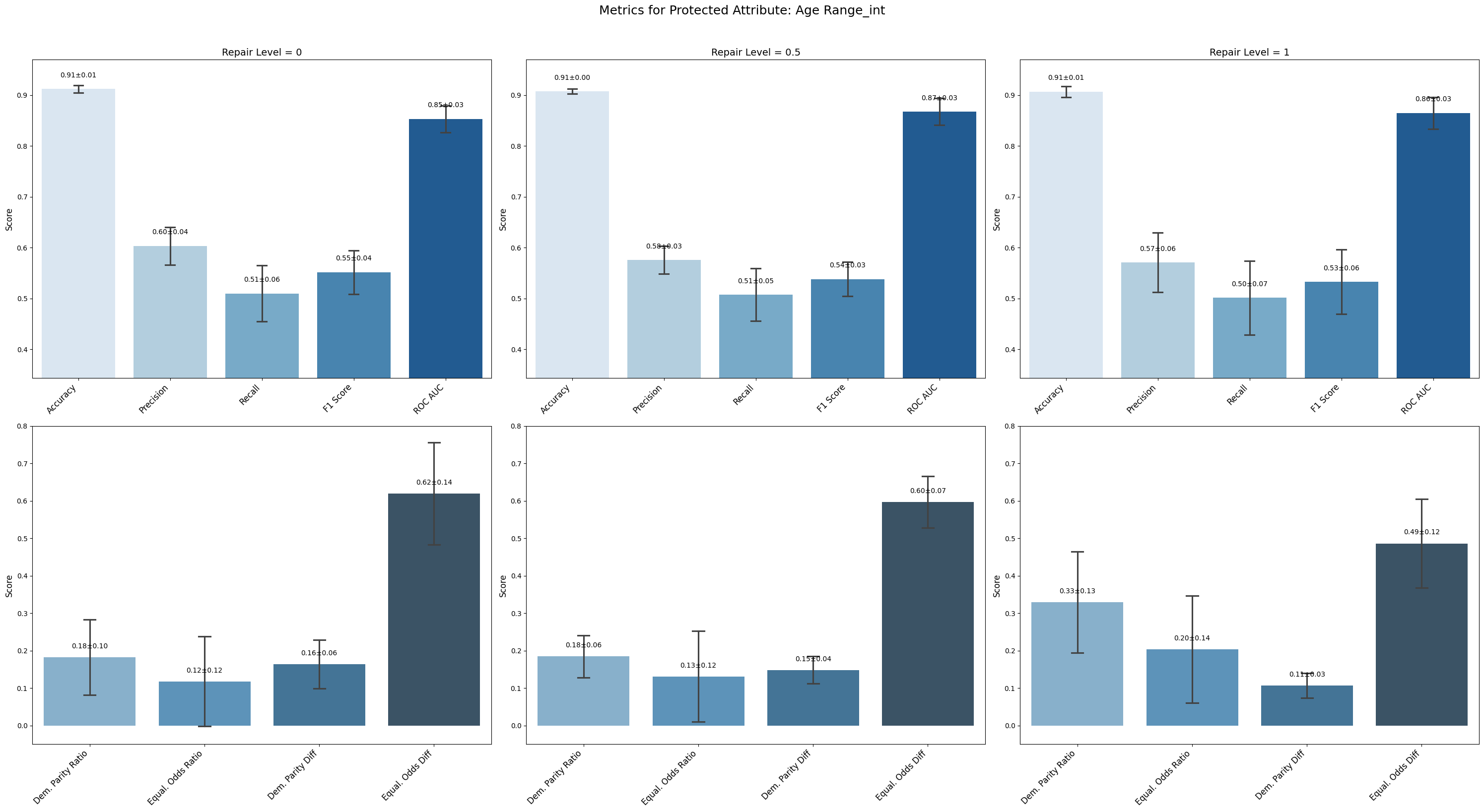
Conclusion on Fauci Repair Method
The Fauci method was evaluated across several sensitive attributes (Sex, Protected Category, Age Range, Italian Residence, and European Residence) using three repair strength levels (Repair 0, 0.5, and 1).
Model Performance:
For Sex_int and Age Range_int, model accuracy and F1 remained relatively stable with minor fluctuations across repair levels. Precision improved slightly for Sex, while recall stayed low or stable.
For Protected Category and European Residence, the model output became uniform, reflected in very low accuracy (~0.106) but perfect recall (1.0), indicating the model predicts only one class regardless of input.
Italian Residence showed inconsistent performance with large variance; accuracy improved from 0.426 to about 0.586 but remained unstable across repairs.
Overall, performance degradation or collapse was evident in location-based attributes due to uniform predictions.
Bias Mitigation:
For Sex_int, equalized odds difference improved modestly from 0.152 to 0.089, suggesting reduced disparity in error rates; demographic parity metrics remained stable.
Protected Category and European Residence achieved perfect demographic parity ratio (1.0) due to uniform outputs, but equalized odds difference stayed high (~0.4 and ~0.8 respectively), indicating persistent bias in error rates.
Age Range_int showed some improvement in fairness: demographic parity ratio increased from 0.182 to 0.330 and equalized odds difference decreased from 0.619 to 0.486, though accompanied by slight drops in precision and F1.
Italian Residence fairness metrics fluctuated without clear improvement; equalized odds ratio stayed at zero, and demographic parity ratio dropped from 0.596 to 0.400, showing inconsistent bias mitigation.
Conclusion: The Fauci method induces mixed effects: while it can slightly reduce some fairness disparities (notably in Sex and Age Range), it often does so at the cost of model performance, especially for geographic attributes where predictions collapse to a single class. Perfect demographic parity achieved via uniform predictions does not translate to balanced fairness in error rates. This suggests the method requires further tuning or combination with other approaches to achieve balanced accuracy and fairness.
Prejudice Remover
results = defaultdict(list)
plot_data = defaultdict(dict)
for fold, (train_idx, test_idx) in tqdm(enumerate(kf.split(dataset, dataset['Hired'])), total=n_folds, desc='Folds...'):
train_df = dataset.iloc[train_idx].copy()
test_df = dataset.iloc[test_idx].copy()
imputer = SimpleImputer(strategy='mean')
train_df = pd.DataFrame(imputer.fit_transform(train_df), columns=train_df.columns)
test_df = pd.DataFrame(imputer.transform(test_df), columns=test_df.columns)
train_df = DataFrame(train_df)
test_df = DataFrame(test_df)
scaler = StandardScaler()
train_df[non_bool_cols] = scaler.fit_transform(train_df[non_bool_cols])
test_df[non_bool_cols] = scaler.transform(test_df[non_bool_cols])
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
train_df.sensitive = sensitive_attr
train_df.targets = 'Hired'
test_df.sensitive = sensitive_attr
test_df.targets = 'Hired'
base_model = base_model_lambda()
model = PrejudiceRemover(
torchModel=base_model,
weight=repair_level
)
model.fit(train_df[features], train_df[['Hired']], num_epochs=20, batch_size=32)
train_probs = model.predict(train_df[features]).numpy()
thresholds = np.linspace(0, 1, 101)
best_threshold = 0.5
best_f1 = 0.0
y_train_true = train_df[['Hired']].values
for thresh in thresholds:
train_preds = (train_probs > thresh).astype(int)
f1 = f1_score(y_train_true, train_preds, zero_division=0)
if f1 > best_f1:
best_f1 = f1
best_threshold = thresh
y_pred = model.predict(test_df[features])
y_prob = y_pred.numpy()
y_pred_binary = (y_prob > best_threshold).astype(int)
y_test = test_df[['Hired']].values
metrics = {
'accuracy': accuracy_score(y_test, y_pred_binary),
'precision': precision_score(y_test, y_pred_binary, zero_division=0),
'recall': recall_score(y_test, y_pred_binary, zero_division=0),
'f1': f1_score(y_test, y_pred_binary, zero_division=0),
'roc_auc': roc_auc_score(y_test, y_prob),
'demographic_parity_ratio': demographic_parity_ratio(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'equalized_odds_ratio': equalized_odds_ratio(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'demographic_parity_difference': demographic_parity_difference(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
'equalized_odds_difference': equalized_odds_difference(
y_test, y_pred_binary, sensitive_features=test_df[sensitive_attr]),
}
key = f"{sensitive_attr}_repair_{repair_level}"
results[key].append(metrics)
metrics_keys = list(metrics.keys())
for sensitive_attr in protected_attributes:
for repair_level in repair_levels:
key = f"{sensitive_attr}_repair_{repair_level}"
fold_metrics = results.get(key, [])
for metric in metrics_keys:
metric_list = [m[metric] for m in fold_metrics]
mean, std = get_mean_std(metric_list)
plot_data[sensitive_attr][f"{metric}_mean_{repair_level}"] = mean
plot_data[sensitive_attr][f"{metric}_std_{repair_level}"] = std
Folds...: 100%|██████████| 5/5 [24:55<00:00, 299.09s/it]
print_fairness_results_table(plot_data, metrics_keys, repair_levels)
=== Results for sensitive attribute: Sex_int ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.907 ± 0.001 0.909 ± 0.005 0.914 ± 0.004
precision 0.567 ± 0.014 0.574 ± 0.018 0.605 ± 0.020
recall 0.543 ± 0.061 0.573 ± 0.071 0.548 ± 0.025
f1 0.552 ± 0.027 0.572 ± 0.039 0.574 ± 0.019
roc_auc 0.886 ± 0.015 0.897 ± 0.020 0.889 ± 0.016
demographic_parity_ratio 0.693 ± 0.134 0.668 ± 0.150 0.572 ± 0.126
equalized_odds_ratio 0.778 ± 0.150 0.729 ± 0.151 0.608 ± 0.141
demographic_parity_difference 0.043 ± 0.019 0.053 ± 0.030 0.066 ± 0.025
equalized_odds_difference 0.075 ± 0.071 0.103 ± 0.072 0.153 ± 0.046
=== Results for sensitive attribute: Protected category ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.909 ± 0.005 0.911 ± 0.010 0.910 ± 0.004
precision 0.583 ± 0.034 0.597 ± 0.051 0.581 ± 0.016
recall 0.539 ± 0.040 0.525 ± 0.068 0.558 ± 0.046
f1 0.558 ± 0.021 0.556 ± 0.051 0.568 ± 0.025
roc_auc 0.889 ± 0.015 0.885 ± 0.019 0.893 ± 0.011
demographic_parity_ratio 0.430 ± 0.380 0.308 ± 0.378 0.487 ± 0.430
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.072 ± 0.046 0.067 ± 0.036 0.066 ± 0.051
equalized_odds_difference 0.446 ± 0.200 0.559 ± 0.047 0.441 ± 0.209
=== Results for sensitive attribute: Age Range_int ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.906 ± 0.007 0.907 ± 0.004 0.912 ± 0.007
precision 0.565 ± 0.037 0.575 ± 0.022 0.592 ± 0.036
recall 0.525 ± 0.068 0.501 ± 0.054 0.558 ± 0.039
f1 0.541 ± 0.042 0.534 ± 0.033 0.574 ± 0.033
roc_auc 0.886 ± 0.022 0.880 ± 0.028 0.892 ± 0.021
demographic_parity_ratio 0.291 ± 0.028 0.280 ± 0.116 0.292 ± 0.040
equalized_odds_ratio 0.197 ± 0.106 0.166 ± 0.099 0.114 ± 0.098
demographic_parity_difference 0.120 ± 0.021 0.128 ± 0.035 0.124 ± 0.019
equalized_odds_difference 0.542 ± 0.118 0.473 ± 0.156 0.448 ± 0.191
=== Results for sensitive attribute: Italian Residence ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.908 ± 0.007 0.909 ± 0.006 0.911 ± 0.007
precision 0.574 ± 0.027 0.580 ± 0.032 0.596 ± 0.040
recall 0.544 ± 0.072 0.526 ± 0.057 0.516 ± 0.045
f1 0.556 ± 0.047 0.550 ± 0.039 0.552 ± 0.036
roc_auc 0.892 ± 0.018 0.883 ± 0.018 0.897 ± 0.013
demographic_parity_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.105 ± 0.012 0.099 ± 0.012 0.097 ± 0.009
equalized_odds_difference 0.644 ± 0.194 0.705 ± 0.246 0.615 ± 0.197
=== Results for sensitive attribute: European Residence ===
Repair 0 Repair 0.5 Repair 1
accuracy 0.911 ± 0.005 0.909 ± 0.004 0.907 ± 0.007
precision 0.594 ± 0.041 0.585 ± 0.026 0.572 ± 0.039
recall 0.527 ± 0.037 0.520 ± 0.035 0.533 ± 0.027
f1 0.556 ± 0.009 0.550 ± 0.017 0.551 ± 0.024
roc_auc 0.887 ± 0.024 0.874 ± 0.017 0.883 ± 0.006
demographic_parity_ratio 0.396 ± 0.335 0.099 ± 0.198 0.093 ± 0.186
equalized_odds_ratio 0.000 ± 0.000 0.000 ± 0.000 0.000 ± 0.000
demographic_parity_difference 0.062 ± 0.039 0.086 ± 0.018 0.091 ± 0.016
equalized_odds_difference 0.529 ± 0.039 0.523 ± 0.037 0.535 ± 0.029
for metric in ['accuracy', 'f1', 'roc_auc', 'demographic_parity_ratio', 'equalized_odds_ratio']:
plot_metrics(plot_data, metric, repair_levels, protected_attributes)
plot_metrics_grouped(results,
protected_attributes=protected_attributes,
repair_levels=repair_levels)
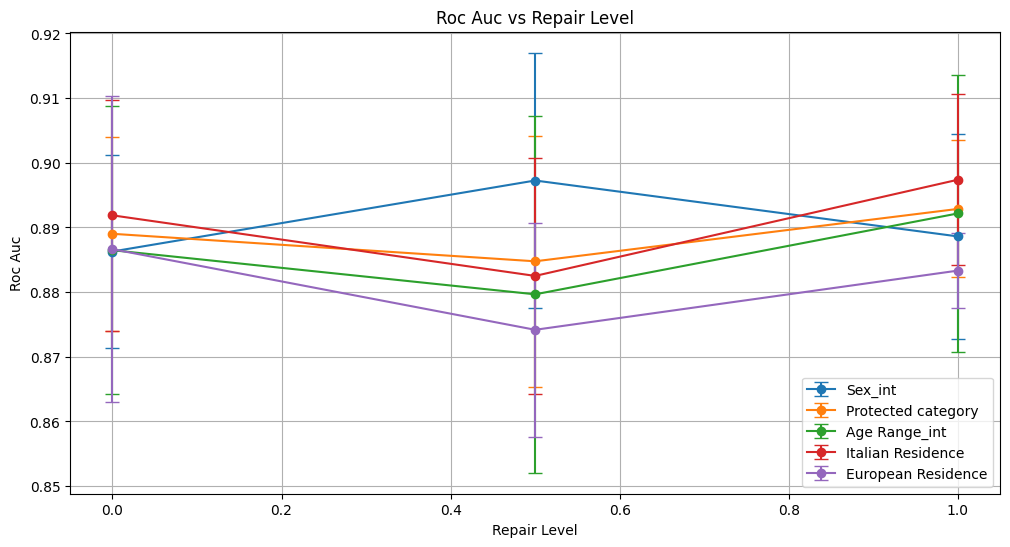
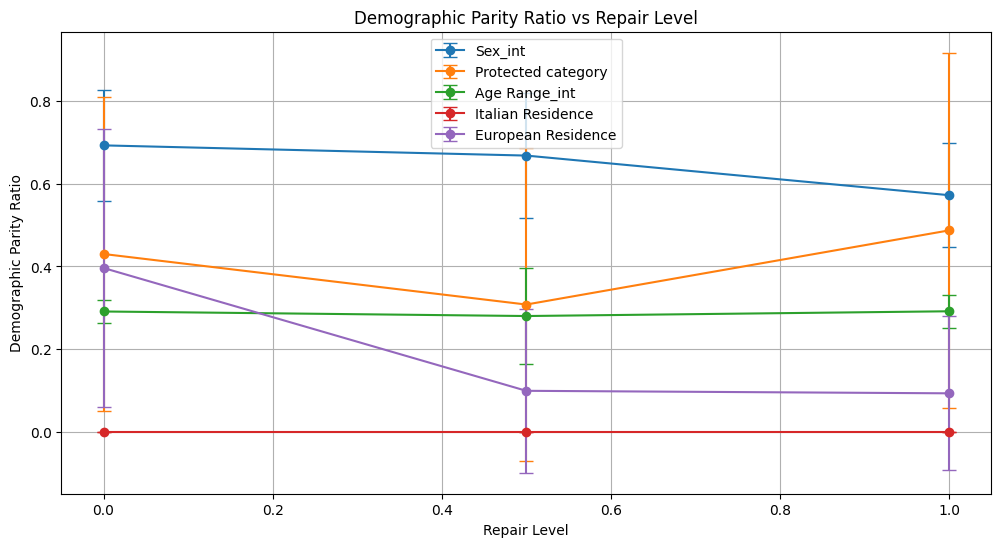
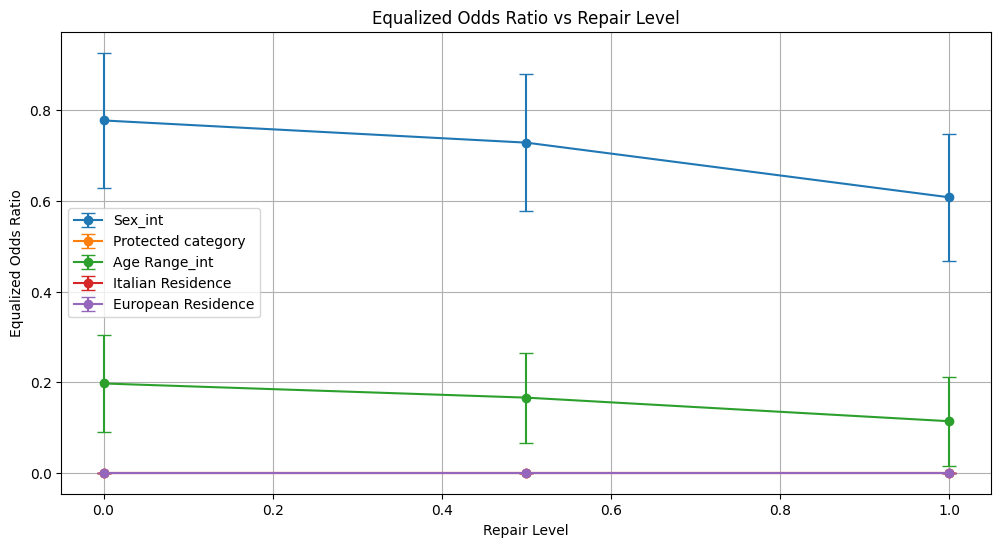
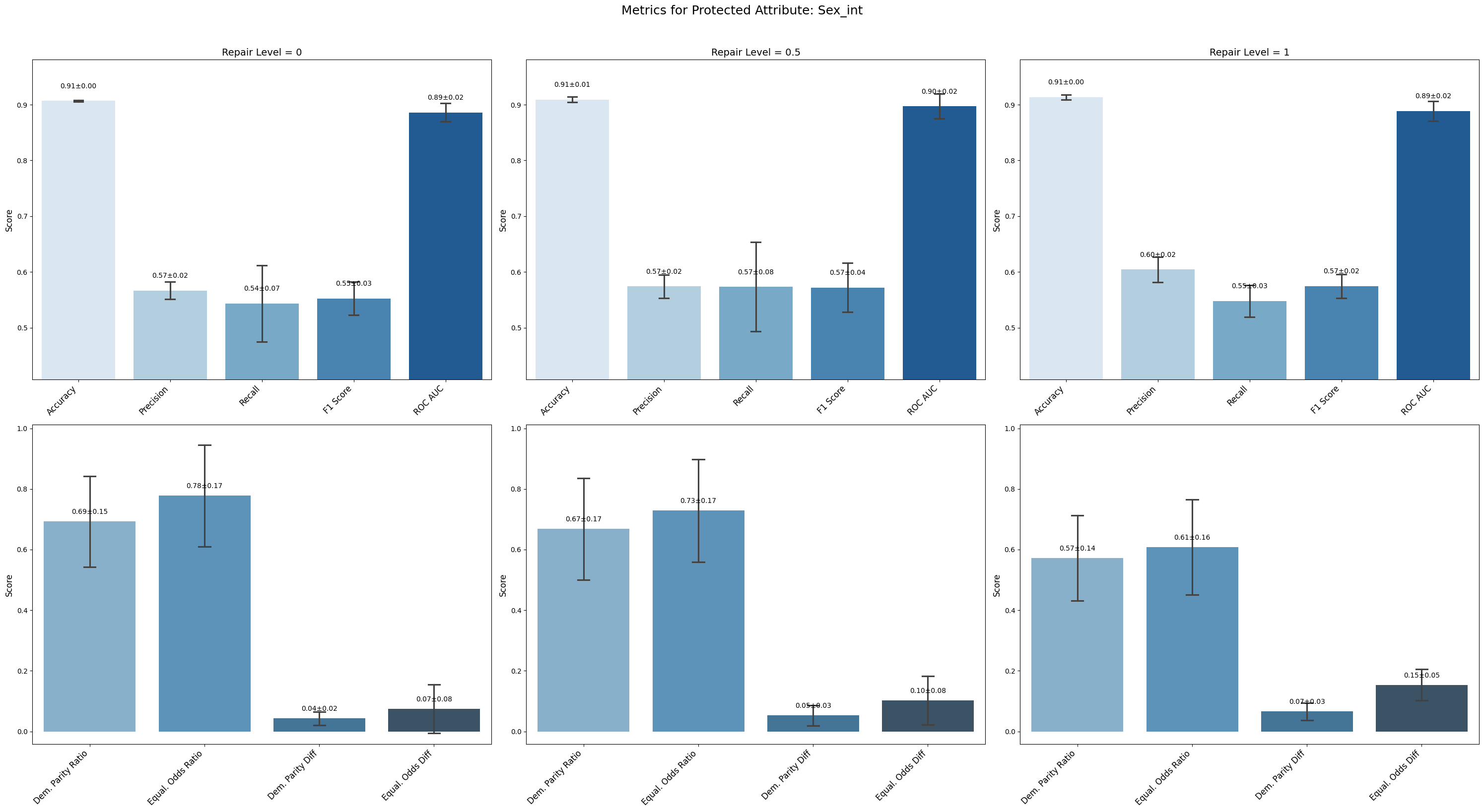
Conclusion on Prejudice Remover Method
The Prejudice Remover method was evaluated at three repair levels (0, 0.5, and 1) across multiple sensitive attributes.
Model Performance:
Accuracy remained consistently high across all attributes and repair levels, ranging from about 0.907 to 0.914.
Other metrics such as precision, recall, F1, and ROC AUC showed minor improvements or remained stable, indicating overall robust predictive performance.
Bias Mitigation:
For Sex_int, precision and F1 improved slightly with repair, but equalized odds difference increased (from 0.075 to 0.153), indicating increased disparity in error rates. Demographic parity difference also showed a slight rise.
Protected Category maintained stable accuracy and precision; however, equalized odds ratio remained at zero for all repair levels, showing no change in fairness. Demographic parity difference remained nearly constant.
Age Range_int showed minor gains in recall and F1, while demographic parity difference and equalized odds difference remained relatively high with slight improvement at higher repair levels.
Italian Residence had no change in demographic parity or equalized odds ratios (both zero), with parity and odds differences remaining elevated throughout.
European Residence saw demographic parity ratio decrease markedly (from 0.396 to 0.093), while equalized odds ratio remained at zero and equalized odds difference stayed high across repair levels.
Conclusion: The method preserves high predictive performance with some improvements in precision and recall but shows limited and inconsistent effects on fairness metrics. Certain attributes, especially Protected Category, Italian Residence, and European Residence, show no meaningful reduction in bias, indicating the method favors accuracy over fairness and may be more suitable where maintaining performance is a priority.